|
Vocapedia
>
Technology > Internet
Search engines, Robotics, A.I, Internet of things
Alphabet, Google
All the world's a platform
As Google celebrates its seventh birthday,
John Battelle examines the potential of a company
that has grown from simple
search engine to technology giant
G
Technology
p. 1
Thursday September 29, 2005
https://www.theguardian.com/media/2005/sep/29/
digitalmedia.technology1
find
information on the Web,
in computer hard drives and e-mail inboxes,
as well as on corporate intranets
hit UK
http://www.guardian.co.uk/technology/2010/mar/21/
facebook-cant-live-without-it
search engines UK
https://www.theguardian.com/technology/
searchengines
http://www.guardian.co.uk/technology/2010/mar/21/
facebook-cant-live-without-it
http://www.nytimes.com/2008/12/10/nyregion/
10about.html
search engines UK
https://www.theguardian.com/technology/
searchengines
http://www.guardian.co.uk/technology/2010/mar/21/
facebook-cant-live-without-it
search engine > Wolfram Alpha USA
http://www.nytimes.com/2012/02/07/technology/
wolfram-a-search-engine-finds-answers-within-itself.html
search engines > Blekko USA
http://www.nytimes.com/2010/11/01/
technology/01search.html
search engines > Microsoft > Bing
USA
http://www.nytimes.com/2009/07/09/
technology/personaltech/09pogue.html
http://www.nytimes.com/2009/05/29/
technology/companies/29soft.html
http://www.nytimes.com/reuters/2009/05/28/
technology/tech-us-microsoft.html
search / search
search features / capabilities
a search entry box
with other options
to
search images, news and the like
search related advertising
search billions of pages
across the internet in a
second
search function
semantic web search > Wolfram Alpha
UK
https://www.wolframalpha.com/
http://www.guardian.co.uk/technology/blog/2009/may/18/
wolfram-alpha-semantic-web-competitor-google
semantic web UK
http://www.theguardian.com/technology/2006/apr/06/
guardianweeklytechnologysection.timbernerslee
meaning
Google > memory UK
http://www.guardian.co.uk/science/2011/jul/15/
poor-memory-blame-google
Google > collective memory
UK
http://www.theguardian.com/lifeandstyle/2014/sep/21/
google-influence-on-collective-memory-lauren-laverne
Google > memory USA
https://www.nytimes.com/2017/05/19/
opinion/sunday/you-still-need-your-brain.html
Google > memorize
USA
https://www.nytimes.com/2017/05/19/
opinion/sunday/you-still-need-your-brain.html
Israeli Archive and Google
Team Up to Put Holocaust Stories at
Fingertips USA
http://www.nytimes.com/2011/02/13/world/middleeast/
13holocaust.html
right to be forgotten requests USA
https://www.npr.org/sections/thetwo-way/2018/02/28/
589411543/google-received-650-000-right-to-be-forgotten-requests-since-2014
online data
database
index
match
podcasts > before 2024

The Economist North
America Edition
Sep 1st 2007
http://www.economist.com/printedition/index.cfm?d=20070901


Jeff Stahler
cartoon
The
Columbus Dispatch
Ohio
Cagle
20 January 2006
http://cagle.msnbc.com/politicalcartoons/PCcartoons/stahler.asp

Randy Siegel NYT October 10, 2005
http://www.nytimes.com/imagepages/2005/10/10/opinion/1010opart.html

Google Gets Better.
What's Up With That?
NYT
26 August 2005
http://www.nytimes.com/2005/08/25/
technology/circuits/25pogue.html
Google FR, UK, USA
https://www.nytimes.com/topic/company/
alphabet-inc
2024
https://www.npr.org/2024/04/19/
1245757317/google-worker-fired-israel-project-nimbus-cloud-protestor
https://www.npr.org/2024/01/04/
1222040458/amazon-google-facebook-twitter-social-media-online
2023
https://www.npr.org/2023/12/13/
1218945531/fortnite-epic-games-google-apple-app-stores
https://www.npr.org/2023/09/05/
1197723820/google-25-ai-youtube-advertising-ceo-nilay-patel-future
https://www.theguardian.com/technology/2023/may/02/
geoffrey-hinton-godfather-of-ai-quits-google-
warns-dangers-of-machine-learning
https://www.nytimes.com/2023/04/16/
technology/google-search-engine-ai.html
2022
https://www.propublica.org/article/
google-human-tissue-jpc-military - December 12, 2022
https://www.propublica.org/article/
google-russia-rutarget-sberbank-sanctions-ukraine - July 1, 2022
2021
https://www.npr.org/2021/01/08/
954710407/at-google-
hundreds-of-workers-formed-a-labor-union-why-to-protect-ourselves
https://www.nytimes.com/2021/01/04/
technology/google-employees-union.html
2020
https://www.npr.org/2020/12/17/
947719354/ousted-black-google-researcher-
they-wanted-to-have-my-presence-but-not-me-exactl
https://www.npr.org/2020/12/17/
947607397/google-hit-with-another-lawsuit-challenging-its-dominance
https://theintercept.com/2020/10/21/
google-cbp-border-contract-anduril/
https://www.nytimes.com/interactive/2020/02/18/
magazine/google-revolt.html
https://www.npr.org/2020/12/03/
941860802/google-illegally-fired-and-spied-
on-workers-who-tried-to-organize-labor-agency-s
2019
https://www.npr.org/2019/11/01/
775419131/google-buys-fitbit-for-2-1-billion-pledges-to-protect-health-data
https://www.theguardian.com/technology/audio/2019/aug/06/
how-much-does-google-know-about-you-podcast
https://www.npr.org/sections/health-shots/2019/04/22/
712778514/google-searches-for-ways-
to-put-artificial-intelligence-to-use-in-health-care
https://www.lemonde.fr/economie/article/2019/01/04/
optimisation-fiscale-google-evite-des-milliards-d-impots-
en-deplacant-toujours-plus-de-profits-aux-bermudes
_5405079_3234.html
2018
https://www.nytimes.com/2018/08/24/
technology/google-china-waymo.html
https://www.nytimes.com/2018/06/01/
technology/google-pentagon-project-maven.html
https://www.nytimes.com/2018/05/30/
technology/google-project-maven-pentagon.html
https://www.theguardian.com/technology/2018/apr/23/
google-owner-alphabet-reports-earnings
https://www.nytimes.com/2018/02/20/
magazine/the-case-against-google.html
2017
https://www.npr.org/sections/alltechconsidered/2017/11/20/
565352403/a-google-related-plan-brings-futuristic-vision-privacy-concerns-to-toronto
https://www.nytimes.com/2017/09/07/
opinion/google-backpagecom-sex-traffickers.html
http://www.npr.org/sections/thetwo-way/2017/08/23/
545482081/walmart-google-join-forces-in-online-fight-against-amazon
https://www.nytimes.com/2017/08/12/
opinion/sunday/google-tech-diversity-memo.html
http://www.npr.org/sections/thetwo-way/2017/08/07/
542020041/google-grapples-with-fallout-after-employee-slams-diversity-efforts
http://www.npr.org/sections/alltechconsidered/2017/08/08/
542210855/google-ceo-cuts-vacation-short-to-deal-with-crisis-over-diversity-memo
http://www.npr.org/sections/thetwo-way/2017/06/26/
534451513/google-says-it-will-no-longer-read-users-emails-to-sell-targeted-ads
https://www.nytimes.com/2017/05/19/
opinion/sunday/you-still-need-your-brain.html
http://www.npr.org/sections/alltechconsidered/2017/05/20/
529146185/in-googles-vision-of-the-future-computing-is-immersive
https://www.nytimes.com/2017/05/13/
technology/google-education-chromebooks-schools.html
http://www.npr.org/2017/05/08/
527214026/google-moves-in-and-wants-to-pump-1-5-million-gallons-of-water-per-day
https://www.nytimes.com/2017/04/22/
opinion/sunday/is-it-time-to-break-up-google.html
http://www.npr.org/sections/thetwo-way/2017/03/21/
520976552/google-promises-to-keep-ads-off-of-hateful-offensive-youtube-content
http://www.npr.org/sections/alltechconsidered/2017/03/18/
514299682/google-glass-didnt-disappear-you-can-find-it-on-the-factory-floor
http://www.npr.org/sections/thetwo-way/2017/01/10/
508363607/what-happened-when-dylann-roof-asked-google-for-information-about-race
2016
http://www.nytimes.com/2016/07/30/
opinion/sunday/the-blog-that-disappeared.html
http://www.npr.org/sections/alltechconsidered/2016/05/
18/478562619/with-new-products-google-flexes-muscles-to-competitors-regulators
http://www.nytimes.com/roomfordebate/2016/04/28/
is-google-a-harmful-monopoly
http://www.npr.org/sections/therecord/2016/02/05/
465703176/maurice-white-the-audacity-of-uplift
2015
http://www.npr.org/sections/ed/2015/11/03/
451999158/the-un-college-thats-training-100-000-app-developers
http://www.npr.org/sections/alltechconsidered/2015/10/16/
449171616/more-fair-use-news-google-books-again-prevails-against-authors
http://www.nytimes.com/2015/08/11/
technology/google-alphabet-restructuring.html
http://www.nytimes.com/2015/05/29/technology/
google-intensifies-focus-on-its-cardboard-virtual-reality-device.html
http://www.theguardian.com/technology/2015/may/28/
google-brillo-operating-system-internet-of-things
http://www.npr.org/sections/alltechconsidered/2015/10/21/
450580490/what-happens-when-the-price-of-free-goes-up-youtubes-about-to-find-out
http://www.nytimes.com/2015/09/13/
opinion/sunday/the-google-art-heist.html
http://www.theguardian.com/lifeandstyle/2014/sep/21/
google-influence-on-collective-memory-lauren-laverne
http://www.nytimes.com/2013/12/03/
technology/google-joins-a-heavyweight-competition-in-cloud-computing.html
http://www.nytimes.com/2013/12/04/technology/
google-puts-money-on-robots-using-the-man-behind-android.html
http://www.nytimes.com/2013/11/01/
technology/angry-over-us-surveillance-tech-giants-bolster-defenses.html
http://www.nytimes.com/2013/06/02/
opinion/sunday/the-banality-of-googles-dont-be-evil.html
http://bits.blogs.nytimes.com/2013/05/16/
google-buys-a-quantum-computer/
http://www.guardian.co.uk/technology/2013/may/02/
how-stop-using-google-search-services
http://www.guardian.co.uk/technology/2013/apr/21/
drones-google-eric-schmidt
http://www.guardian.co.uk/technology/2013/apr/20/
eric-schmidt-google-alan-rusbridger
http://www.nytimes.com/2013/01/14/technology/
google-gains-from-creating-apps-for-the-opposition.html
http://www.nytimes.com/2013/01/05/opinion/
is-google-like-gas-or-like-steel.html
http://www.nytimes.com/2013/01/06/opinion/sunday/
google-wins-an-antitrust-battle.html
http://www.nytimes.com/2013/01/04/technology/
googles-lawyers-work-behind-the-scenes-to-carry-the-day.html
http://www.nytimes.com/2012/12/26/
technology/google-apps-moving-onto-microsofts-business-turf.html
http://www.nytimes.com/2012/11/04/
technology/google-casts-a-big-shadow-on-smaller-web-sites.html
http://www.guardian.co.uk/technology/2012/aug/05/
google-fast-to-deliver-broadband-revolution
http://www.guardian.co.uk/technology/2012/jun/18/
google-reports-alarming-rise-censorship
http://www.nytimes.com/2012/05/22/
business/global/europe-warns-google-over-antitrust.html
http://www.nytimes.com/2012/04/29/
technology/google-engineer-told-others-of-data-collection-fcc-report-reveals.html
http://www.nytimes.com/2012/03/01/
technology/impatient-web-users-flee-slow-loading-sites.html
http://www.nytimes.com/2012/02/23/
technology/google-glasses-will-be-powered-by-android.html
http://bits.blogs.nytimes.com/2012/02/21/
google-to-sell-terminator-style-glasses-by-years-end/
http://www.nytimes.com/2012/02/10/
technology/google-at-work-on-an-entertainment-device.html
http://loyalopposition.blogs.nytimes.com/2012/01/18/
behold-the-power-of-google/
http://www.nytimes.com/2012/01/02/
technology/google-hones-its-advertising-message-playing-to-emotions.html
http://www.nytimes.com/2011/11/10/
technology/googles-chief-works-to-trim-a-bloated-ship.html
http://www.nytimes.com/2011/09/19/
technology/googles-to-face-congressional-antitrust-hearing.html
http://www.nytimes.com/2011/08/16/
technology/google-deal-could-strain-ties-with-phone-makers.html
http://dealbook.nytimes.com/2011/08/15/
googles-big-bet-on-the-mobile-future/
http://www.nytimes.com/2011/05/10/
technology/10google.html
http://www.guardian.co.uk/technology/2011/apr/07/
google-to-boost-spend-on-original-youtube-content
http://www.reuters.com/article/2011/04/04/us-
google-idUSTRE7334Z020110404
http://www.nytimes.com/2011/02/13/world/middleeast/
13holocaust.html
http://www.nytimes.com/2011/02/13/business/13search.html
http://www.nytimes.com/2011/01/30/business/30charity.html
http://www.nytimes.com/2011/01/22/technology/22google.html
http://www.nytimes.com/2011/01/21/technology/21google.html
http://www.guardian.co.uk/technology/2011/jan/21/google-larry-page-ceo-schmidt
http://www.nytimes.com/2010/12/02/technology/02ranking.html
http://www.nytimes.com/2010/11/25/technology/25chrome.html
http://www.nytimes.com/2010/11/18/fashion/18googlefashion.html
http://www.nytimes.com/2010/11/16/business/media/16adco.html
http://www.guardian.co.uk/technology/blog/2010/nov/08/google-facebook-gmail-contacts-data
http://www.nytimes.com/2010/11/02/technology/02google.html
http://bits.blogs.nytimes.com/2010/11/01/google-extends-security-reward-program/
http://www.nytimes.com/2010/09/23/technology/23facebook.html
http://www.nytimes.com/2010/09/09/technology/techspecial/09google.html
http://www.nytimes.com/aponline/2010/07/16/business/AP-US-Earns-Google.html
http://www.nytimes.com/2010/07/16/technology/16google.html
http://www.nytimes.com/2010/07/02/technology/02google.html
http://www.guardian.co.uk/technology/2010/jun/10/google-image-front-page
http://www.nytimes.com/2010/05/22/technology/22admob.html
http://www.nytimes.com/2010/05/21/technology/21google.html
http://www.nytimes.com/2010/05/21/technology/21streetview.html
http://bits.blogs.nytimes.com/2010/05/20/
live-blogging-the-google-tv-and-android-announcements/
http://www.nytimes.com/2010/05/17/technology/17youtube.html
http://www.nytimes.com/reuters/2010/05/12/technology/tech-us-microsoft-office.html
http://www.nytimes.com/2010/04/16/technology/16google.html
http://www.guardian.co.uk/technology/2010/mar/21/facebook-cant-live-without-it
http://www.guardian.co.uk/music/2010/feb/11/google-deletes-music-blogs
http://www.nytimes.com/2010/02/11/technology/companies/11google.html
http://www.guardian.co.uk/technology/2010/feb/09/facebook-google-news-search
http://www.nytimes.com/2009/12/08/technology/companies/08google.html
http://www.guardian.co.uk/media/2009/dec/02/google-online-news-rupert-murdoch
http://www.guardian.co.uk/media/2009/jul/20/google-defamation-high-court-ruling
http://www.nytimes.com/2009/07/09/technology/personaltech/09pogue.html
http://www.nytimes.com/2009/06/14/business/14digi.html
http://www.guardian.co.uk/technology/2008/may/22/internet.google
http://www.guardian.co.uk/business/2008/apr/17/useconomy.google
https://www.theguardian.com/media/2007/may/12/newmedia.news
https://www.theguardian.com/technology/2007/apr/30/news.citynews
http://www.theguardian.com/media/2006/nov/16/business.news
http://www.theguardian.com/society/2006/nov/10/health.lifeandhealth
https://www.theguardian.com/technology/2006/nov/02/searchengines.newmedia
https://www.theguardian.com/technology/2006/oct/24/news.politicsandthemedia
https://www.theguardian.com/business/2006/oct/11/businesscomment.digitalmedia
http://business.guardian.co.uk/story/0,,1891792,00.html
http://business.guardian.co.uk/story/0,,1889927,00.html
http://media.guardian.co.uk/site/story/0,,1865925,00.html
http://books.guardian.co.uk/news/articles/0,,1861685,00.html
https://www.theguardian.com/business/2006/aug/29/digitalmedia.advertising
https://www.theguardian.com/world/2006/aug/28/germany.lukeharding
https://www.theguardian.com/technology/2006/jul/13/news.broadcasting
https://www.theguardian.com/technology/2006/jul/12/searchengines.newmedia
https://www.theguardian.com/media/2006/jul/06/pressandpublishing.digitalmedia
https://www.theguardian.com/technology/2006/jul/06/comment.newmedia
https://www.theguardian.com/technology/2006/jun/08/news.newmedia
https://www.theguardian.com/technology/2006/may/23/searchengines.news
https://www.theguardian.com/technology/2006/jan/25/news.citynews
https://www.theguardian.com/technology/2006/jan/25/searchengines.citynews
https://www.theguardian.com/technology/2006/jan/23/news.filmnews
https://www.theguardian.com/technology/2006/jan/19/newmedia.media
https://www.theguardian.com/technology/2006/jan/18/searchengines.citynews
https://www.theguardian.com/technology/2006/jan/16/searchengines.farrightpolitics
http://www.economist.com/business/displaystory.cfm?story_id=5382048
http://www.nytimes.com/2006/01/06/technology/06online.html
http://www.theguardian.com/media/2006/jan/03/newmedia.news
https://www.theguardian.com/business/2005/dec/21/newmedia.media
http://www.nytimes.com/2005/11/20/business/yourmoney/20digi.html
http://www.nytimes.com/2005/11/06/technology/06google.html
http://www.nytimes.com/2005/10/30/business/yourmoney/30google.html
http://www.nytimes.com/2005/11/02/technology/02soft.html
http://www.nytimes.com/2005/11/03/business/media/03google.html
http://www.nytimes.com/2005/08/25/technology/circuits/25pogue.html
http://www.nytimes.com/2005/08/22/technology/22google.html
https://www.theguardian.com/business/2005/aug/18/searchengines.china
https://www.theguardian.com/salon/
story/0,14752,1331700,00.html - 20 October 2004
Google’s ad business
USA
https://www.propublica.org/article/
google-display-ads-piracy-porn-fraud - December 21, 2022
Google > advertising revenue
USA
http://www.nytimes.com/2013/11/19/
technology/google-to-pay-17-million-to-settle-privacy-case.html
elaborate avoidance scheme > Google FR
https://www.lemonde.fr/economie/article/2019/01/04/
optimisation-fiscale-google-evite-des-milliards-d-impots-
en-deplacant-toujours-plus-de-profits-aux-bermudes
_5405079_3234.html
online retailing service > Google Express
USA
http://www.npr.org/sections/thetwo-way/2017/08/23/
545482081/walmart-google-join-forces-in-online-fight-against-amazon
voice-activated speaker Google Home
USA
http://www.npr.org/sections/thetwo-way/2017/08/23/
545482081/walmart-google-join-forces-in-online-fight-against-amazon
Google Assistant app
http://www.npr.org/sections/thetwo-way/2017/08/23/
545482081/walmart-google-join-forces-in-online-fight-against-amazon
Google Now
USA
http://www.nytimes.com/2015/11/30/
technology/personaltech/how-to-use-google-now-on-tap.html
Artificial
Intelligence A.I.
USA
https://theintercept.com/2020/10/21/
google-cbp-border-contract-anduril/
https://www.npr.org/sections/health-shots/2019/04/22/
712778514/google-searches-for-ways-to-put-artificial-intelligence-to-use-in-health-care
virtual reality VR USA
http://www.npr.org/sections/alltechconsidered/2017/05/20/
529146185/in-googles-vision-of-the-future-computing-is-immersive
http://www.nytimes.com/2015/09/29/
technology/google-virtual-reality-system-aims-to-enliven-education.html
virtual reality
viewer > Cardboard USA
http://www.nytimes.com/2015/05/29/
technology/google-intensifies-focus-on-its-cardboard-virtual-reality-device.html
The Internet of
Things / fully connected houses Brillo
operating system UK
http://www.theguardian.com/technology/2015/may/28/
google-brillo-operating-system-internet-of-things
EU Charges Google
With Antitrust Violations USA
http://www.npr.org/blogs/thetwo-way/2015/04/15/
399788719/eu-charges-google-with-antitrust-violations-will-also-look-at-android
USA > Google > Google's co-founder Larry Page
UK / USA
https://www.theguardian.com/media/larrypage
https://www.nytimes.com/topic/person/larry-page
http://www.guardian.co.uk/technology/2013/jan/18/
google-larry-page-facebook-apple
http://www.nytimes.com/2011/11/10/
technology/googles-chief-works-to-trim-a-bloated-ship.html
http://www.nytimes.com/2011/01/22/
technology/22google.html
Google > Google's co-founder Sergey Brin
UK
https://www.theguardian.com/media/sergeybrin
http://www.guardian.co.uk/technology/2012/apr/18/
google-sergey-brin-web-freedom
Google chairman Eric Schmidt
UK
https://www.theguardian.com/technology/eric-schmidt
http://www.theguardian.com/technology/2014/mar/07/
google-eric-schmidt-jared-cohen
http://www.guardian.co.uk/technology/2012/may/23/
google-fund-teachers-computer-science-uk
Google > stock market
USA
http://www.nytimes.com/2013/10/19/
technology/google-stock-scales-1000-a-share.html
Googlization
https://www.ucpress.edu/book.php?isbn=9780520258822
Googleplex
Froogle
Google Russia UK
http://www.guardian.co.uk/world/2010/feb/16/
google-tran-siberian-express-tour
Google vs Microsoft USA
http://www.nytimes.com/2012/12/26/
technology/google-apps-moving-onto-microsofts-business-turf.html
http://www.nytimes.com/reuters/2010/05/12/
technology/tech-us-microsoft-office.html
Google > data denters >
electricity / Google carbon
footprint UK/USA
http://www.guardian.co.uk/environment/2011/sep/08/
google-carbon-footprint
http://www.nytimes.com/2011/09/09/
technology/google-details-electricity-output-of-its-data-centers.html
Google > privacy UK / USA
https://www.theguardian.com/technology/audio/2019/aug/06/
how-much-does-google-know-about-you-podcast
http://www.nytimes.com/2016/04/25/
opinion/europes-web-privacy-rules-bad-for-google-bad-for-everyone.html
http://www.theguardian.com/world/2014/aug/03/
internet-death-privacy-google-facebook-alex-preston
http://www.nytimes.com/2014/05/21/
opinion/dowd-remember-to-forget.html
http://www.theguardian.com/technology/2014/may/17/
google-privacy-ruling-thin-end-censorship-wedge
http://www.nytimes.com/2014/05/15/
opinion/dont-force-google-to-forget.html
http://www.nytimes.com/2013/10/02/
technology/google-accused-of-wiretapping-in-gmail-scans.html
http://www.nytimes.com/2012/12/08/
technology/eu-panel-to-pressure-google-on-privacy-rules.html
http://www.guardian.co.uk/technology/2012/oct/16/
google-privacy-policies-eu-data-protection
http://www.nytimes.com/2012/04/29/
technology/google-engineer-told-others-of-data-collection-fcc-report-reveals.html
http://www.guardian.co.uk/technology/2012/apr/22/
me-and-my-data-internet-giants
http://www.guardian.co.uk/news/datablog/2012/apr/22/
download-your-data-google-facebook
http://www.guardian.co.uk/technology/2012/apr/22/
big-data-privacy-information-currency
http://www.guardian.co.uk/technology/2012/mar/03/
internet-privacy
http://www.guardian.co.uk/technology/2012/feb/24/
pass-notes-browsing
http://www.guardian.co.uk/technology/2010/oct/26/
google-street-view-privacy
http://www.nytimes.com/2010/05/28/
technology/28google.html
http://www.nytimes.com/2010/05/22/
technology/22streetview.html
http://www.nytimes.com/2010/05/21/
technology/21streetview.html
Google > privacy > Europe > the 'right to be forgotten' 2014
http://www.theguardian.com/technology/2014/aug/02/
wikipedia-page-google-link-hidden-right-to-be-forgotten
http://www.nytimes.com/2014/07/04/
technology/google-starts-erasing-links-for-searches-in-europe.html
http://www.nytimes.com/2014/05/21/
opinion/dowd-remember-to-forget.html
http://www.theguardian.com/technology/2014/may/17/
google-privacy-ruling-thin-end-censorship-wedge
Google > mass surveillance UK / USA
https://www.theguardian.com/technology/audio/2019/aug/06/
how-much-does-google-know-about-you-podcast
erase links
USA
http://www.nytimes.com/2014/07/04/
technology/google-starts-erasing-links-for-searches-in-europe.html
privacy > use of personal data
gleaned from Internet searches
USA
http://www.nytimes.com/2013/11/19/
technology/google-to-pay-17-million-to-settle-privacy-case.html
http://www.nytimes.com/2012/02/23/
business/white-house-outlines-online-privacy-guidelines.html
users’ endorsements
USA
http://www.nytimes.com/2013/10/12/
technology/google-sets-plan-to-sell-users-endorsements.html
collate the reams
of personal information shared online
in the chase for profits
USA
http://www.nytimes.com/2013/10/12/
technology/google-sets-plan-to-sell-users-endorsements.html
Google > scan emails in Gmail
accounts
in order sell targeted advertising
USA
http://www.npr.org/sections/thetwo-way/2017/06/26/
534451513/google-says-it-will-no-longer-read-users-emails-to-sell-targeted-ads
Apple’s Feud With Google USA
http://www.nytimes.com/2012/09/24/
technology/apples-feud-with-google-is-now-felt-on-the-iphone.html
Google’s massive
humanoid robot UK
http://www.theguardian.com/technology/2015/jan/21/
googles-massive-humanoid-robot-can-now-walk-and-move-without-wires
Google > Robotics
USA
2014-2015
http://bits.blogs.nytimes.com/2015/03/27/
google-and-johnson-johnson-team-for-robotic-surgery-projects/
http://www.npr.org/blogs/alltechconsidered/2014/03/17/
290888529/with-googles-robot-buying-binge-a-hat-tip-to-the-future
self-driving cars USA
http://www.npr.org/sections/alltechconsidered/2016/02/24/
467983440/google-makes-the-case-for-a-hands-off-approach-to-self-driving-cars
Google > the 'internet of things'
UK
2014
http://www.theguardian.com/technology/2014/jan/14/
how-google-home-nest-labs-acquisition
Google Project Glass
UK / USA
Google goggles / Augmented reality
glasses 2012-2014
eyeglasses
that will project
information,
entertainment
and (...) advertisements
onto the lenses
https://www.theguardian.com/technology/
google-glass
http://www.npr.org/sections/alltechconsidered/2017/03/18/
514299682/google-glass-didnt-disappear-you-can-find-it-on-the-factory-floor
http://well.blogs.nytimes.com/2014/06/01/
google-glass-enters-the-operating-room/
http://www.npr.org/blogs/itsallpolitics/2014/03/17/
290714189/google-glass-coming-soon-to-a-campaign-trail-near-you
http://www.nytimes.com/2013/05/26/
opinion/sunday/google-glass-may-be-hands-free-but-not-brain-free.html
http://www.guardian.co.uk/technology/2013/apr/30/
google-glass-pictures-online
http://www.guardian.co.uk/technology/2013/mar/09/
google-glass-geek-aesthetics-fashion
http://www.guardian.co.uk/technology/2013/mar/06/
google-glass-threat-to-our-privacy
http://www.guardian.co.uk/technology/2013/jan/21/
sergey-brin-google-glass-new-york-subway
http://www.guardian.co.uk/technology/2012/apr/05/
google-project-glass-digital-goggles
http://www.nytimes.com/2012/02/23/
technology/google-glasses-will-be-powered-by-android.html
http://bits.blogs.nytimes.com/2012/02/21/
google-to-sell-terminator-style-glasses-by-years-end/
augmented reality UK
https://www.theguardian.com/technology/
augmented-reality
Google Reader
USA
is what’s called,
somewhat geekily,
a newsreader,
or painfully geekily,
an RSS aggregator.
It’s like an online newspaper
you assemble yourself
from Web pages all over the world.
Instead of sitting down
at your desk each morning
and visiting each of your favorites sites in turn
— say, NYtimes.com, Reddit.com
and HuffingtonPost.com —
you just open reader.google.com.
There, you find a tidy list
of all the new articles from all
of those sources,
organized like an e-mail Inbox.
You skim the headlines, you read summaries,
you click the ones that seem worth reading.
http://www.nytimes.com/2013/05/09/
technology/personaltech/three-ways-feedly-
outdoes-the-vanishing-google-reader.html
Google Wallet mobile payments system
UK
http://www.guardian.co.uk/technology/2011/sep/19/
google-wallet-available-public
Google Instant Pages UK
http://www.guardian.co.uk/technology/2011/jun/14/
google-instant-pages-web-search
Google TV USA
http://www.nytimes.com/2010/12/21/
technology/21sony.html
http://www.nytimes.com/2010/05/21/
technology/21google.html
Google browser > Chrome
UK
http://www.guardian.co.uk/technology/2012/jan/03/
google-ban-browser-index
Google laptop computers > Chromebooks
UK
http://www.guardian.co.uk/technology/blog/2011/jun/15/
google-chromebook-os-microsoft-threat
http://www.guardian.co.uk/technology/2011/may/12/
google-microsoft-chromebook-laptop
Chrome operating system
USA
http://www.nytimes.com/2010/05/09/business/09ping.html
Google's front page
UK
http://www.guardian.co.uk/technology/2010/jun/10/google-image-front-page
Google doodle
UK
http://www.guardian.co.uk/technology/google-doodle
http://www.guardian.co.uk/culture/2010/oct/16/
oscar-wilde-birthday-google-doodle
Google Buzz > privacy
USA
http://www.nytimes.com/2010/02/15/
technology/internet/15google.html
http://www.nytimes.com/2010/02/13/
technology/internet/13google.html
Google announces payment system
for digital content > Google One
Pass USA
http://www.nytimes.com/2011/02/17/
business/media/17google.html
Google’s first Pixel smartwatch
UK
https://www.theguardian.com/technology/2022/oct/20/
google-pixel-watch-review-good-first-attempt
Google's Android operating system
for mobile phones
https://www.theguardian.com/technology/android
http://www.nytimes.com/2010/07/12/
technology/12google.html
http://www.guardian.co.uk/technology/2010/may/17/
android-mobile-phones-google
http://www.guardian.co.uk/technology/2010/may/10/
google-android-outsells-apple-iphone
Google App Inventor for Android
http://www.nytimes.com/2010/07/12/technology/12google.html
Google Nexus 4
http://www.guardian.co.uk/technology/2013/jan/02/
nexus-4-review
Google phone > 'Nexus One'
http://www.guardian.co.uk/technology/2012/dec/08/tablet-christmas-google-apple
http://www.guardian.co.uk/technology/2012/nov/05/nexus-10-review
http://www.nytimes.com/2010/01/13/technology/companies/13google.html
http://www.guardian.co.uk/technology/2009/dec/14/google-nexusone
Google Inactive Account Manager
(the) program called
Inactive Account
Manager,
introduced in April, (..)
lets those who use Google services
decide exactly
how they want
to deal with the data
they’ve stored online with the company
— from Gmail and Picasa photo albums
to publicly shared data
like YouTube videos and blogs.
The process is straightforward.
First go to google.com/settings/account.
Then look for “account management”
and then “control what happens to your account
when you stop using Google.”
Click on “Learn more and go to setup.”
Then let Google know
the people you want to be notified
when the company deactivates the account;
you’re allowed up to 10 names.
You choose when you want Google
to end your account
— for example, after three,
six or nine months of electronic silence
(or even 12 months,
if you’ve decided
to take a yearlong trip down the Amazon).
http://www.nytimes.com/2013/05/26/technology/
estate-planning-is-important-for-your-online-assets-too.html
Google Docs
http://www.nytimes.com/reuters/2010/05/12/
technology/tech-us-microsoft-office.html
Google > Google Translate service
https://translate.google.com/
http://www.nytimes.com/2010/03/09/
technology/09translate.html
YouTube,
a subsidiary of the search giant
Google UK / USA
http://www.npr.org/sections/alltechconsidered/2015/10/21/
450580490/what-happens-when-the-price-of-free-goes-up-youtubes-about-to-find-out
http://www.guardian.co.uk/technology/2011/apr/07/
google-to-boost-spend-on-original-youtube-content
http://www.nytimes.com/2010/05/17/
technology/17youtube.html
Google's power-hungry data centres
UK
http://www.guardian.co.uk/technology/2009/may/03/
google-data-centres
Google's data centers
USA
http://www.npr.org/2017/05/08/
527214026/google-moves-in-and-wants-to-pump-1-5-million-gallons-of-water-per-day
Google > cloud-based software
USA
http://www.nytimes.com/2012/12/26/
technology/google-apps-moving-onto-microsofts-business-turf.html
Google's cloud-based music player
Allowing people to upload and store
their music collections on the Web
and listen to their songs
on Android phones or tablets
and on computers
http://www.nytimes.com/2011/05/10/
technology/10google.html
"+1" button
https://developers.google.com/search/blog/2011/03/introducing-1-button
Google Art Project
Google's Street View-style
inventory of the world's great galleries
https://artsandculture.google.com/
http://www.theguardian.com/artanddesign/2014/jun/11/
google-street-art-project-graffiti
http://www.guardian.co.uk/artanddesign/jonathanjonesblog/2011/feb/01/
google-art-project-painting-reproduction
Google's Street View service UK / USA
https://www.google.co.uk/intl/en-GB/streetview/
https://archive.nytimes.com/bits.blogs.nytimes.com/2014/06/30/
supreme-court-rejects-googles-street-view-appeal/
https://www.theguardian.com/cities/ng-interactive/2014/jun/12/
google-street-view-sleuth-problems-mapped
https://www.theguardian.com/technology/2014/apr/23/
google-introduces-time-machine-feature-in-street-view
https://www.theguardian.com/cities/gallery/2014/feb/25/
london-paintings-google-street-view-canaletto-1
http://www.nytimes.com/2011/11/15/nyregion/
google-takes-central-parks-picture-for-online-strolling.html
http://www.nytimes.com/2010/11/11/technology/11google.html
http://www.theguardian.com/technology/2010/nov/19/google-street-view-data
http://www.nytimes.com/2010/10/28/technology/28google.html
http://www.ftc.gov/os/closings/101027googleletter.pdf
http://www.guardian.co.uk/technology/2010/oct/26/google-street-view-privacy
http://www.nytimes.com/2010/10/16/technology/16streetview.html
http://www.nytimes.com/2010/06/04/business/global/04google.html
http://www.nytimes.com/2010/05/16/technology/16google.html
http://www.guardian.co.uk/technology/2010/may/15/google-admits-storing-private-data
http://www.nytimes.com/2010/05/15/business/15google.html
http://www.independent.co.uk/life-style/gadgets-and-tech/news/
http://www.independent.co.uk/opinion/commentators/
ross-clark-snapshots-are-not-an-issue-of-privacy-1651168.html
http://www.telegraph.co.uk/technology/google/7493217/
Google-Street-View-forced-to-remove-images-of-secret-British-security-bases.html
http://www.guardian.co.uk/technology/2009/mar/21/google-street-view-privacy-images
http://www.guardian.co.uk/artanddesign/gallery/2009/mar/20/
canvas-tate-landscapes-google-street-view?picture=344845167
http://www.guardian.co.uk/technology/2008/jul/31/google.civilliberties
Google map USA
http://www.nytimes.com/2013/12/15/
magazine/googles-plan-for-global-domination-dont-ask-why-ask-where.html
Google map > Trekker
USA
http://www.nytimes.com/2013/12/15/
magazine/googles-plan-for-global-domination-dont-ask-why-ask-where.html
Google Library Project (Google Book Search)
Google > Plans to scan books
Google's
controversial plan
to digitise millions of books /
Google's online library plans
/
Google book
search
https://www.nytimes.com/topic/company/
google-library-project-google-book-search
http://www.npr.org/sections/alltechconsidered/2015/10/16/
449171616/more-fair-use-news-google-books-again-prevails-against-authors
http://www.guardian.co.uk/technology/2011/mar/23/google-online-library-plans-thwarted
http://www.guardian.co.uk/books/2010/feb/23/authors-opt-out-google-book-settlement
http://www.nytimes.com/2009/10/09/opinion/09brin.html
http://www.nytimes.com/2009/10/07/technology/internet/07google.html
http://www.nytimes.com/2009/09/08/technology/internet/08books.html
http://www.nytimes.com/2009/09/08/technology/internet/08books.html
http://www.nytimes.com/2009/05/21/technology/companies/21google.html
http://www.theguardian.com/books/2006/mar/04/featuresreviews.guardianreview28
Google crawler
crawl
google
UK
http://www.theguardian.com/technology/2006/dec/11/
news.iran
google
USA
http://www.npr.org/sections/alltechconsidered/2016/02/05/
465699380/ok-google-where-did-i-put-my-thinking-cap
http://opinionator.blogs.nytimes.com/2015/04/04/
do-you-google-your-shrink/
type ... into Google
http://www.nytimes.com/2010/10/06/
science/06stem.html
Google > cartoons > Cagle
http://www.cagle.com/news/Google/main.asp

Doonesbury
By Garry Trudeau
political cartoon
GoComics
26 June 2011
https://www.gocomics.com/doonesbury/2011/06/26
search
search / web search
UK / USA
http://www.nytimes.com/2013/04/04/
technology/as-web-search-goes-mobile-apps-chip-at-googles-lead.html
http://www.guardian.co.uk/commentisfree/2013/feb/05/
can-googling-be-racist
https://www.gocomics.com/doonesbury/2011/06/26
http://www.nytimes.com/2010/09/09/
technology/techspecial/09google.html
googling
http://www.nytimes.com/2015/09/27/
opinion/sunday/stop-googling-lets-talk.html
Googling my brain
20 October 2004
https://www.theguardian.com/
salon/story/0,14752,1331700,00.html
Google and the future of search:
Amit Singhal and the Knowledge Graph
2013
Google has revolutionised
the way we holiday, shop, work and play.
Now, with Knowledge Graph,
it plans to radically transform
the way we search the internet… again.
But some voice qualms
about the company's ambitions
http://www.guardian.co.uk/technology/2013/jan/19/
google-search-knowledge-graph-singhal-interview
Google’s Search Pages Evolve
2012
Google’s look has changed significantly
since it started in
1997.
While the search engine originally returned
basic blue links to other Web pages,
it now also shows ads, photos, maps,
answers to questions and other information.
While Google says this helps users
get the information they want
as quickly as
possible,
some of its competitors say Google
is poaching potential visitors
to their sites by showing its own content
and including eye candy like photos and maps.
Antitrust regulators are investigating.
http://www.nytimes.com/interactive/2012/11/03/
technology/search-compare.html
Google new search tool / the "knowledge graph"
2012 UK
http://www.guardian.co.uk/technology/2012/may/16/
google-unleashes-new-seach-tool
Google search algorithm
USA
http://bits.blogs.nytimes.com/2011/11/03/
google-changes-search-algorithm-trying-to-make-results-more-timely/
search results
USA
https://www.npr.org/2021/10/27/
1049736477/google-minors-remove-images-search-results
search results / rank / ranking
demote
http://www.nytimes.com/2012/11/04/
technology/google-casts-a-big-shadow-on-smaller-web-sites.html
Google’s data centres
http://www.guardian.co.uk/technology/2013/jan/19/
google-search-knowledge-graph-singhal-interview
web-search company
ad
Google’s ad business > disinformation
USA
https://www.propublica.org/article/
google-alphabet-ads-fund-disinformation-covid-elections - October 29, 2022
widget
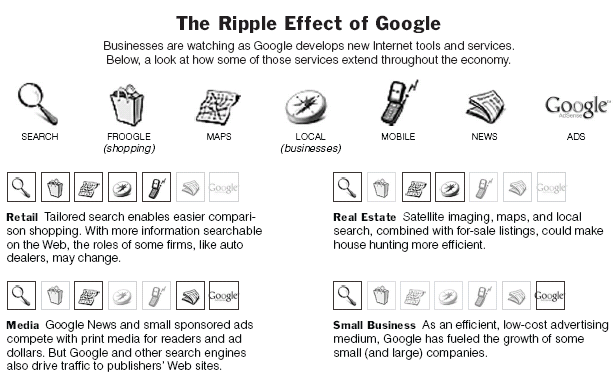
Just Googling It Is Striking Fear Into Companies
By STEVE LOHR NYT November 6, 2005
https://www.nytimes.com/2005/11/06/technology/
just-googling-it-is-striking-fear-into-companies.html

Google Wants to Dominate Madison Avenue, Too
By SAUL HANSELL NYT October 30, 2005
https://www.nytimes.com/2005/10/30/
business/yourmoney/google-wants-to-dominate-madison-avenue-too.html
M. e. Cohen
New
Jersey, Freelance
Cagle
2.6.2005
http://cagle.msnbc.com/politicalcartoons/PCcartoons/cohen.asp
Sorry, an error has occurred.
The requested document was not
found on this site.
This could be for a variety of reasons, including:
You followed a broken or out-of-date link.
You entered the URL incorrectly.
The file no longer exists.
If you have any queries about this error,
please e-mail the website administrator
support@ichelp.co.uk.
we're sorry... This story
is not available.
This page has expired.
To retrieve this story please visit our archive at...
Page not found.
We are
redesigning our site,
and
the link chosen may now be
invalid.
We apologize for the oversight.
Please choose from the options below:
Try the 'not found' page again
Go back to the previous page
Go to the Reuters home page
If the difficulties persist,
you may wish to send a
message to the Help Desk
Page not found
We couldn't find the
page you were
looking for.
This website has recently
been relaunched
which means that some bookmarks to old pages
may no longer work.
Authorization Server Error
We're sorry,
but we are
temporarily experiencing an
authorization server error.
Our systems administrators have been notified
and
are
working to fix the problem.
Please click here to continue
logging in.
We regret the inconvenience.
General Error
We are
experiencing technical difficulties at this time.
Our apologies
for the inconvenience.
Please choose from the options below:
Go to the page you were
just on
Try the request again
Go to the Reuters home page
If the difficulties persist,
you
may wish to send a
message to the Help Desk.
Sorry.
We have not been able
to serve the page you asked
for.
The Digital Edition archive stores 13 editions of
the Guardian
and four editions of the Observer at any one time.
If you follow a bookmark or link to a Digital
Edition page
after it has expired from the archive,
you will see this message.
For all other problems,
please email full details
to subshelp@guardian.co.uk.
Please include the
following:
The URL you were trying to access and,
if
applicable, the URL of the page you came from
A full description of the problem,
including what you were
trying to do and what happened.
The more detail, the better
The time and date you encountered the bug.
This will help us to identify
bugs
relating to any changes or updates we make
over time
The type and version of internet browser you were
using
The PC/Mac and operating system you were using
The page could not
be loaded.
If you have typed the URL in
by hand
then please make sure you
have entered it correctly.
Alternatively,
if you have come from a link within
the site and found this page,
please click on the link below to register a
technical problem
that we will correct as soon as
possible!
Or select the back to the Times Online link
to
return to the Times Online homepage.
There are no records that
match your search.
Press the Back button on your browser to
return to the search page.
No results matched that query.
Please refine your search.
General Error
We are
experiencing technical difficulties at this time.
Our apologies
for the inconvenience. (163-0)
Please choose from the options
below:
Go to the page you were just on
Try the request again
Go to the Reuters home page
If the difficulties persist,
you
may wish to send a
message to the Help Desk
Server Application Unavailable
The web application
you are
attempting to access on this web
server
is currently unavailable.
Please hit the "Refresh" button
in your web browser
to retry your request.
Administrator Note:
An error message detailing the cause
of this specific request failure
can be found
in the application event log of the web server.
Please review this log entry
to
discover what caused
this error to occur.
Server Error
The server encountered a temporary error
and
could not complete
your request.
Please try again in 30 seconds.
Network Error (gateway_error)
An error occurred
attempting to
communicate with an HTTP or SOCKS gateway.
The gateway may be temporarily unavailable,
or
there could be a network problem.
For assistance, contact your network support team.
Corpus of news articles
Technology > Internet
Search engines, Robotics, A.I, Internet
of things
Alphabet, Google
Don’t Force Google to ‘Forget’
MAY 14, 2014
The New York Times
The Opinion Pages
Op-Ed Contributor
By JONATHAN ZITTRAIN
CAMBRIDGE, Mass. — THE European Court of Justice ruled on
Tuesday that Europeans have a limited “right to be forgotten” by search engines
like Google. According to the ruling, an individual can compel Google to remove
certain reputation-harming search results that are generated by Googling the
individual’s name. The court is trying to address an important problem — namely,
the Internet’s ability to preserve indefinitely all its information about you,
no matter how unfortunate or misleading — but it has devised a poor solution.
The court’s decision is both too broad and curiously narrow. It is too broad in
that it allows individuals to impede access to facts about themselves found in
public documents. This is a form of censorship, one that would most likely be
unconstitutional if attempted in the United States. Moreover, the test for
removal that search engines are expected to use is so vague — search results are
to be excluded if they are “inadequate, irrelevant or no longer relevant” — that
search engines are likely to err on the safe side and accede to most requests.
But the decision is oddly narrow in that it doesn’t require that unwanted
information be removed from the web. The court doesn’t have a problem with web
pages that mention the name of the plaintiff in this case (Mario Costeja
González) and the thing he regrets (a property foreclosure); it has a problem
only with search engines that list those pages — including this article and
possibly the court’s own ruling — as results to a query on the basis of Mr.
González’s name. So nothing is being “forgotten,” despite the court’s stated
attempt to protect such a right.
How an individual’s reputation is protected online is too important and subtle a
policy matter to be legislated by a high court, which is institutionally
mismatched to the evolving intricacies of the online world.
Progress has been limited perhaps by a shortfall of imagination by Google,
Microsoft’s Bing and the handful of other powerful intermediaries who stand
between what we ask and what we’re told is relevant. Search engines generally
treat personal names as search terms like any others: Data is data. Google and
company have not internalized just how significant that first page of search
results has become to someone whose name has been queried. What they place on
that page may do more than anything else in the world to define a stranger in
others’ estimations.
What if search engine companies were to think more creatively about how such
searches might work? In 2007, Google admirably experimented in this area,
introducing a feature to its Google News aggregator that allowed people quoted
or mentioned in a news article indexed by Google News to add a comment next to
that article in the search results. Such participants could offer readers of
Google News an explanation, an apology, or a reason to discount whatever it was
they were about to read. (Academics were among the first users of the feature,
often adding a comment to contextualize something a newspaper reporter had
quoted them as saying.) But Google ultimately abandoned the feature.
That’s too bad. If search engines allowed for such comments generally, they
might be able to give you more influence over the information about you online —
without giving you the power to censor. Perhaps querying someone’s name would
result in an initial page of search results in which some form of curating was
permitted for people sharing that name; the subsequent pages of results would
provide the unvarnished material that a regular search now generates.
For those who believe in a right to “be forgotten,” such a proposal would of
course fall short. But I suspect that in many cases, the desire for such a right
is merely the desire not to have your life presented to the world
mechanistically and without review, with nothing more than a search term and a
single click. This is a legitimate desire that the sort of proposal I have in
mind would satisfy.
Whatever the solution, the status quo is no longer stable. In the wake of the
decision by the European Court of Justice, search engine companies now face a
potential avalanche of requests for redaction. And whatever the merits of the
court’s decision, Europe cannot expect to export its new approach to countries
like the United States. (Even in Europe, search engine users will no doubt
cultivate the same Internet “workarounds” that Chinese citizens use to see what
their government doesn’t want them to see.)
Google, Bing and Yahoo should devote their considerable resources to mitigating
this problem. If they don’t, search engine results may become increasingly
dependent on where your keyboard is, rather than what you’re looking for. And
the search engines may find themselves in a cat-and-mouse game of censorship and
evasion, leading only to a fragmentation, not an improvement, of the web.
Jonathan Zittrain, a professor of law and computer scienc
at Harvard, is the author of “The Future of the Interne
— And How to Stop It.”
A version of this op-ed appears in print on May 15, 2014,
on page A29 of the New York edition with the headline:
Don’t Force Google to ‘Forget’.
Don’t Force Google to ‘Forget’,
NYT,
14.5.2014,
https://www.nytimes.com/2014/05/15/
opinion/dont-force-google-to-forget.html
In Web
Search,
Be Efficient in the Terms You Use
October 24,
2012
The New York Times
By THOMAS J. FITZGERALD
By this
point in the Internet era, everyone should know how to find information on the
Web with a search engine like Google or Bing.
Easy, right? Just type what you are looking for in the little box.
There are even easier ways. Google and Bing have built right into their search
boxes tools like calculators, currency converters and dictionaries. They
developed a host of tricks you can use to slice through clutter to reach the
information you need. In some cases the results appear right away; you don’t
need to touch the enter key. Many of the shortcuts work with the Web browsers on
smartphones and tablets.
“We really try to make Bing a place where you can go to get stuff done in the
real world,” said Stefan Weitz, senior director of Bing, Microsoft’s search
engine and chief rival to Google. “People expect search now to actually do a
better job connecting them to the ultimate destination.” If you need any
additional help, Google also offers online tutorials.
TRAVEL TOOLS A fast way to find driving directions with Google is to type your
query directly in the search box, using the following format: from 1380 Mass
Ave, Cambridge, MA to 815 Boylston Street, Boston. The result is a map along
with driving distance, trip time and a link to directions.
If you are planning air travel, you can track fares and be directed to sites for
ticket purchases. In the Google search box, type airport codes in the following
way: BOS to ABQ. An initial listing of flights appears, along with drop-down
calendars to select departure and return dates.
If you click on the “Flights from Boston to Albuquerque” link, you arrive at a
more extensive tool for finding flight information, including a lowest fares
calculator, available by clicking the small graph-shaped button, or an
interactive map, by clicking the balloon button, where you can choose among
different departure or destination cities.
Bing’s tool for air travel can be found using the same format of entering
airport codes in the search box, and when you drill down further you have
choices of buying tickets through sources like Travelocity, Priceline and
Expedia.
With either Bing or Google, you can quickly check flight status using the
following format: Delta flight status 1512.
Also useful for travelers are language translation tools. In either Bing or
Google, use the following format: translate coffee to Turkish. The result,
kahve, appears, and if you click the first link you can find tools for
translating words into dozens of languages.
Converting currencies is also available by using the following format in either
search engine: 100 U.S. dollars in Indian rupees.
In both search engines, to book reservations at restaurants, the search results
for a restaurant in a major city will often include a link to OpenTable, a
provider of restaurant reservations. (You may need to add a ZIP code or a city
name for common names.) The right-hand column might also have other information
like reviews and maps.
SOCIAL NETWORKS Both Google and Microsoft have been trying to figure out how
best to interact with the trove of information locked away in social networking
sites like Facebook, LinkedIn and Twitter.
Microsoft has entered into partnerships with Facebook and others allowing Bing
users to connect with people who may know something about their search query.
You can log into a Facebook account from the Bing home page, and while you
search in Bing, a sidebar appears along the right side of the results page that
may display Facebook friends who have some relationship to your search.
If your query is “Mexican restaurants in San Antonio,” and you hover over the
image of a friend, you may see a Facebook comment or photo of their favorite
place for good mole.
Google has its own social networking service, Google Plus, which enables users
to share their favorite search results with friends also on the service.
SPECIALIZED SEARCHES Much has changed since the early days of search engines,
and given the vastness of data now available online, knowing a few simple yet
powerful shortcuts can pinpoint information more relevant to your search.
You can dig through the Web for specific kinds of files, for example PowerPoint
files related to the Affordable Care Act. In Google use the format filetype:ppt
the affordable care act. (The ppt part of the query is the extension for
PowerPoint files.) Other popular extensions are docx, xlsx and pdf, for Word,
Excel and PDF files. Bing flips the search format — type the affordable care act
filetype:ppt.
Another very useful way to dig for information is to use the prefix site: to
search within a site. For example, type site:washingtonpost.com Mitt Romney to
get links to articles, blog posts and other references to Mitt Romney that
appeared in The Washington Post. Bing reverses the format — type Mitt Romney
site:washingtonpost.com.
To save time, in some instances you can preview information in search results.
To preview videos without having to click on them, in the results page of Bing
hover over the image of a video and in many cases it will play. And in Google
you can see previews of Web pages by moving the cursor to the right of a search
result and hovering over a small image of double arrows.
FINDING FACTS If you need a calculator, both Google and Bing can calculate some
pretty fancy math queries by entering them in the search box, but Google goes
further. Type 4 * 24 in Google and the answer appears as you finish typing, and
below that emerges an in-browser calculator with scientific functions. You can
also turn Google’s search box into a trigonometric graphing calculator; type,
for example, cos(x) + cos(y) and a rotating three-dimensional graph is
displayed. From there you can size the graph or grab it to view it from
different angles.
Converting measurements is easy using the following format in either search
engine: pints in a gallon; centimeters in a foot.
Stock prices are available in either Google or Bing by entering a stock symbol —
followed by “stock” if there is any ambiguity. For example aapl stock or sbux
stock, pulls up prices of Apple or Starbucks. In Google, using a company name
works: Whole Foods stock.
Dictionaries are available as well by using the following format: define
perspicacity.
Weather forecasts are quickly at hand by entering a ZIP code or city name, in
either Google or Bing, as in weather Denver.
Likewise, to find movies playing in your area, all you need is your ZIP code:
movies 10018. (Type in an actor or director followed by the word movies to see
what else he or she did.)
But, if you are looking for someone to take out to a movie and impress with all
your newfound knowledge, there is no search algorithm just yet. For that, you
are still on your own.
In Web Search, Be Efficient in the Terms You Use,
NYT, 25.10.2012,
http://www.nytimes.com/2012/10/25/
technology/personaltech/tips-to-search-smarter-and-faster.html
As Violence Spreads in Arab World,
Google Blocks Access
to Inflammatory Video
September 13, 2012
The New York Times
By CLAIRE CAIN MILLER
SAN FRANCISCO — As violence spread in the Arab world over a
video on YouTube ridiculing the Prophet Muhammad, Google, the owner of YouTube,
blocked access to it in two of the countries in turmoil, Egypt and Libya, but
did not remove the video from its Web site.
Google said it decided to block the video in response to violence that killed
four American diplomatic personnel in Libya. The company said its decision was
unusual, made because of the exceptional circumstances. Its policy is to remove
content only if it is hate speech, violating its terms of service, or if it is
responding to valid court orders or government requests. And it said it had
determined that under its own guidelines, the video was not hate speech.
Millions of people across the Muslim world, though, viewed the video as one of
the most inflammatory pieces of content to circulate on the Internet. From
Afghanistan to Libya, the authorities have been scrambling to contain an
outpouring of popular outrage over the video and calling on the United States to
take measures against its producers.
Google’s action raises fundamental questions about the control that Internet
companies have over online expression. Should the companies themselves decide
what standards govern what is seen on the Internet? How consistently should
these policies be applied?
“Google is the world’s gatekeeper for information so if Google wants to define
the First Amendment to exclude this sort of material then there’s not a lot the
rest of the world can do about it,” said Peter Spiro, a constitutional and
international law professor at Temple University in Philadelphia. “It makes this
episode an even more significant one if Google broadens the block.”
He added, though, that “provisionally,” he thought Google made the right call.
“Anything that helps calm the situation, I think is for the better.”
Under YouTube’s terms of service, hate speech is speech against individuals, not
against groups. Because the video mocks Islam but not Muslim people, it has been
allowed to stay on the site in most of the world, the company said Thursday.
“This video — which is widely available on the Web — is clearly within our
guidelines and so will stay on YouTube,” it said. “However, given the very
difficult situation in Libya and Egypt we have temporarily restricted access in
both countries.”
Though the video is still visible in other Arab countries where violence has
flared, YouTube is closely monitoring the situation, according to a person
briefed on YouTube’s decision-making who was not authorized to speak publicly.
The Afghan government has asked YouTube to remove the video, and some Google
services were blocked there Thursday.
Google is walking a precarious line, said Kevin Bankston, director of the free
expression project at the Center for Democracy and Technology, a nonprofit in
Washington that advocates for digital civil liberties.
On the one hand, he said, blocking the video “sends the message that if you
violently object to speech you disagree with, you can get it censored.” At the
same time, he said, “the decision to block in those two countries specifically
is kind of hard to second guess, considering the severity of the violence in
those two areas.”
“It seems they’re trying to balance the concern about censorship with the threat
of actual violence in Egypt and Libya,” he added. “It’s a difficult calculation
to make and highlights the difficult positions that content platforms are
sometimes put in.”
All Web companies that allow people to post content online — Facebook and
Twitter as well as Google — have grappled with issues involving content. The
questions are complicated by the fact that the Internet has no geographical
boundaries, so companies must navigate a morass of laws and cultural mores. Web
companies receive dozens of requests a month to remove content. Google alone
received more than 1,965 requests from government agencies last year to remove
at least 20,311 pieces of content, it said.
These included a request from a Canadian government office to remove a video of
a Canadian citizen urinating on his passport and flushing it down the toilet,
and a request from a Pakistan government office to remove six videos satirizing
Pakistani officials. In both cases, Google refused to remove the videos.
But it did block access in Turkey to videos that exposed private details about
public officials because, in response to Turkish government and court requests,
it determined that they violated local laws.
Similarly, in India it blocked local access to some videos of protests and those
that used offensive language against religious leaders because it determined
that they violated local laws prohibiting speech that could incite enmity
between communities.
Requests for content removal from United States governments and courts doubled
over the course of last year to 279 requests to remove 6,949 items, according to
Google. Members of Congress have publicly requested that YouTube take down
jihadist videos they say incite terrorism, and in some cases YouTube has agreed.
Google has continually fallen back on its guidelines to remove only content that
breaks laws or its terms of service, at the request of users, governments or
courts, which is why blocking the anti-Islam video was exceptional.
Some wonder what precedent this might set, especially for government authorities
keen to stanch expression they think will inflame their populace.
“It depends on whether this is the beginning of a trend or an extremely
exceptional response to an extremely exceptional situation,” said Rebecca
MacKinnon, co-founder of Global Voices, a network of bloggers worldwide, and
author of “Consent of the Networked,” a book that addresses free speech in the
digital age.
Somini Sengupta contributed reporting.
As Violence Spreads in Arab World,
Google
Blocks Access to Inflammatory Video,
NYT, 13.9.2012,
http://www.nytimes.com/2012/09/14/technology/
google-blocks-inflammatory-video-in-egypt-and-libya.html
Data Harvesting at Google
Not a Rogue Act, Report Finds
April 28, 2012
The New York Times
By DAVID STREITFELD
SAN FRANCISCO — Google’s harvesting of e-mails, passwords and
other sensitive personal information from unsuspecting households in the United
States and around the world was neither a mistake nor the work of a rogue
engineer, as the company long maintained, but a program that supervisors knew
about, according to new details from the full text of a regulatory report.
The report, prepared by the Federal Communications Commission after a 17-month
investigation of Google’s Street View project, was released, heavily redacted,
two weeks ago. Although it found that Google had not violated any laws, the
agency said Google had obstructed the inquiry and fined the company $25,000.
On Saturday, Google released a version of the report with only employees’ names
redacted.
The full version draws a portrait of a company where an engineer can easily
embark on a project to gather personal e-mails and Web searches of potentially
hundreds of millions of people as part of his or her unscheduled work time, and
where privacy concerns are shrugged off.
The so-called payload data was secretly collected between 2007 and 2010 as part
of Street View, a project to photograph streetscapes over much of the civilized
world. When the program was being designed, the report says, it included the
following “to do” item: “Discuss privacy considerations with Product Counsel.”
“That never occurred,” the report says.
Google says the data collection was legal. But when regulators asked to see what
had been collected, Google refused, the report says, saying it might break
privacy and wiretapping laws if it shared the material.
A Google spokeswoman said Saturday that the company had much stricter privacy
controls than it used to, in part because of the Street View controversy. She
expressed the hope that with the release of the full report, “we can now put
this matter behind us.”
Ever since information about the secret data collection first began to emerge
two years ago, Google has portrayed it as the mistakes of an unauthorized
engineer operating on his own and stressed that the data was never used in any
Google product.
The report, quoting the engineer’s original proposal, gives a somewhat different
impression. The data, the engineer wrote, would “be analyzed offline for use in
other initiatives.” Google says this was never done.
The report, which was first published in its unredacted form by The Los Angeles
Times, also states that the engineer, who began the project as part of his “20
percent” time that Google gives employees to do work on their own initiative,
“specifically told two engineers working on the project, including a senior
manager, about collecting payload data.”
As early as 2007, the report says, Street View engineers had “wide access” to
the plan to collect payload data. Five engineers tested the Street View code, a
sixth reviewed it line by line, and a seventh also worked on it, the report
says.
Privacy advocates said the full report put Google in a bad light.
“Google’s rogue engineer scenario collapses in light of the fact that others
were aware of the project and did not object,” said Marc Rotenberg, executive
director of the Electronic Privacy Information Center. “This is what happens in
the absence of enforcement and the absence of regulation.”
The Street View program used special cars outfitted with cameras. Google first
said it was just photographing streets and did not disclose that it was
collecting Internet communications called payload data, transmitted over Wi-Fi
networks, until May 2010, when it was confronted by German regulators.
Eventually, it was forced to reveal that the information it had collected could
include the full text of e-mails, sites visited and other data.
Even if a user was not working on a computer at the moment the Street View car
slowly passed, if the device was on and the network was unencrypted, all sorts
of information about what the user had been doing could be scooped up, data
experts say.
“So how did this happen? Quite simply, it was a mistake,” a Google executive
wrote on a company blog in 2010. “The project leaders did not want, and had no
intention of using, payload data.”
But according to the report, the engineer suggested in his proposal that it was
entirely intentional: “We are logging user traffic along with sufficient data to
precisely triangulate their position at a given time, along with information
about what they were doing.”
Attending to paperwork did not seem to be a high priority, however. Managers of
the Street View project told F.C.C. investigators that they never read the
engineer’s proposal, called a design document. A senior manager of Street View
said he “preapproved” the document before it was written.
More than a dozen countries began investigations of Street View in 2010. In the
United States, the Justice Department, the Federal Trade Commission, state
attorneys general and the F.C.C. looked into the matter.
The engineer at the center of the project cited the Fifth Amendment protection
against self-incrimination. Because F.C.C. investigators could not interview
him, they said there were still unresolved questions about the case.
Data Harvesting at Google Not a Rogue Act,
Report Finds,
NYT, 28.4.2012,
http://www.nytimes.com/2012/04/29/technology/
google-engineer-told-others-of-data-collection-fcc-report-reveals.html
For Impatient Web Users,
an Eye Blink Is Just Too Long to Wait
February 29, 2012
The New York Times
By STEVE LOHR
Wait a second.
No, that’s too long.
Remember when you were willing to wait a few seconds for a computer to respond
to a click on a Web site or a tap on a keyboard? These days, even 400
milliseconds — literally the blink of an eye — is too long, as Google engineers
have discovered. That barely perceptible delay causes people to search less.
“Subconsciously, you don’t like to wait,” said Arvind Jain, a Google engineer
who is the company’s resident speed maestro. “Every millisecond matters.”
Google and other tech companies are on a new quest for speed, challenging the
likes of Mr. Jain to make fast go faster. The reason is that data-hungry
smartphones and tablets are creating frustrating digital traffic jams, as people
download maps, video clips of sports highlights, news updates or recommendations
for nearby restaurants. The competition to be the quickest is fierce.
People will visit a Web site less often if it is slower than a close competitor
by more than 250 milliseconds (a millisecond is a thousandth of a second).
“Two hundred fifty milliseconds, either slower or faster, is close to the magic
number now for competitive advantage on the Web,” said Harry Shum, a computer
scientist and speed specialist at Microsoft.
The performance of Web sites varies, and so do user expectations. A person will
be more patient waiting for a video clip to load than for a search result. And
Web sites constantly face trade-offs between visual richness and snappy response
times. As entertainment and news sites, like The New York Times Web site, offer
more video clips and interactive graphics, that can slow things down.
But speed matters in every context, research shows. Four out of five online
users will click away if a video stalls while loading.
On a mobile phone, a Web page takes a leisurely nine seconds to load, according
to Google, which tracks a huge range of sites from the homes of large companies
to the legions of one-person bloggers. Download times on personal computers
average about six seconds worldwide, and about 3.5 seconds on average in the
United States. The major search engines, Google and Microsoft’s Bing, are the
speed demons of the Web, analysts say, typically delivering results in less than
a second.
The hunger for speed on smartphones is a new business opportunity for companies
like Akamai Technologies, which specializes in helping Web sites deliver
services quicker. Later this month, Akamai plans to introduce mobile accelerator
software to help speed up the loading of a Web site or app.
The government too recognizes the importance of speed in mobile computing. In
February, Congress opened the door to an increase in network capacity for mobile
devices, proposing legislation that permits the auction of public airwaves now
used for television broadcasts to wireless Internet suppliers.
Overcoming speed bumps is part of the history of the Internet. In the 1990s, as
the World Wide Web became popular, and crowded, it was called the World Wide
Wait. Invention and investment answered the call.
Laying a lot of fiber optic cable for high-speed transmission was the first
solution. But beyond bandwidth, the Web got faster because of innovations in
software algorithms for routing traffic, and in distributing computer servers
around the world, nearer to users, as a way to increase speed.
Akamai, which grew out of the Massachusetts Institute of Technology’s Laboratory
for Computer Science, built its sizable business doing just that. Most major Web
sites use Akamai’s technology today.
The company sees the mobile Internet as the next big challenge. “Users’
expectations are getting shorter and shorter, and the mobile infrastructure is
not built for that kind of speed,” said Tom Leighton, co-founder and chief
scientist at Akamai, who is also an M.I.T. professor. “And that’s an opportunity
for us.”
The need for speed itself seems to be accelerating. In the early 1960s, the two
professors at Dartmouth College who invented the BASIC programming language,
John Kemeny and Thomas Kurtz, set up a network in which many students could tap
into a single, large computer from keyboard terminals.
“We found,” they observed, “that any response time that averages more than 10
seconds destroys the illusion of having one’s own computer.”
In 2009, a study by Forrester Research found that online shoppers expected pages
to load in two seconds or fewer — and at three seconds, a large share abandon
the site. Only three years earlier a similar Forrester study found the average
expectations for page load times were four seconds or fewer.
The two-second rule is still often cited as a standard for Web commerce sites.
Yet experts in human-computer interaction say that rule is outdated. “The old
two-second guideline has long been surpassed on the racetrack of Web
expectations,” said Eric Horvitz, a scientist at Microsoft’s research labs.
Google, which harvests more Internet ad revenue than any other company, stands
to benefit more than most if the Internet speeds up. Mr. Jain, who worked at
Microsoft and Akamai before joining Google in 2003, is an evangelist for speed
both inside and outside the company. He leads a “Make the Web Faster” program,
begun in 2009. He also holds senior positions in industry standards groups.
Speed, Mr. Jain said, is a critical element in all of Google’s products. There
is even a companywide speed budget; new offerings and product tweaks must not
slow down Google services. But there have been lapses.
In 2007, for example, after the company added popular new offerings like Gmail,
things slowed down enough that Google’s leaders issued a “Code Yellow” and
handed out plastic stopwatches to its engineers to emphasize that speed matters.
Still, not everyone is in line with today’s race to be faster. Mr. Kurtz, the
Dartmouth computer scientist who is the co-inventor of BASIC, is now 84, and
marvels at how things have changed.
Computers and networks these days, Mr. Kurtz said, “are fast enough for me.”
For Impatient Web Users, an Eye Blink Is
Just Too Long to Wait,
NYT, 29.2.2012,
http://www.nytimes.com/2012/03/01/technology/
impatient-web-users-flee-slow-loading-sites.html
Behind the Google Goggles,
Virtual Reality
February 22, 2012
The New York Times
By NICK BILTON
SAN FRANCISCO — It wasn’t so long ago that legions of people
began walking the streets, talking to themselves.
On closer inspection, many of them turned out to be wearing tiny earpieces that
connected wirelessly to their smartphones.
What’s next? Perhaps throngs of people in thick-framed sunglasses lurching down
the streets, cocking and twisting their heads like extras in a zombie movie.
That’s because later this year, Google is expected to start selling eyeglasses
that will project information, entertainment and, this being a Google product,
advertisements onto the lenses. The glasses are not being designed to be worn
constantly — although Google engineers expect some users will wear them a lot —
but will be more like smartphones, used when needed, with the lenses serving as
a kind of see-through computer monitor.
“It will look very strange to onlookers when people are wearing these glasses,”
said William Brinkman, graduate director of the computer science and software
engineering department at Miami University in Oxford, Ohio. “You obviously won’t
see what they can from the behind the glasses. As a result, you will see bizarre
body language as people duck or dodge around virtual things.”
Mr. Brinkman, whose work focuses on augmented reality or the projection of a
layer of information over physical objects, said his students had experimented
on their own with virtual games and obstacle courses. “It looks really weird to
outsiders when you watch people navigate these spaces,” he said.
They have not seen the Google glasses. Few people have, because they are being
built in the Google X offices, a secretive laboratory near Google’s main
Mountain View, Calif., campus where engineers and scientists are also working on
robots and space elevators.
The glasses will use the same Android software that powers Android smartphones
and tablets. Like smartphones and tablets, the glasses will be equipped with GPS
and motion sensors. They will also contain a camera and audio inputs and
outputs.
Several people who have seen the glasses, but who are not allowed to speak
publicly about them, said that the location information was a major feature of
the glasses. Through the built-in camera on the glasses, Google will be able to
stream images to its rack computers and return augmented reality information to
the person wearing them. For instance, a person looking at a landmark could see
detailed historical information and comments about it left by friends. If facial
recognition software becomes accurate enough, the glasses could remind a wearer
of when and how he met the vaguely familiar person standing in front of him at a
party. They might also be used for virtual reality games that use the real world
as the playground.
People flailing their arms in midair as they play those games is a potentially
humorous outcome of the virtual reality glasses. In a more serious vein is the
almost certain possibility of privacy issues and ubiquitous advertisements. When
someone is meeting a person for the first time, for example, Google could
hypothetically match the person’s face and tell people how many friends they
share in common on social networks.
This month, the Electronic Privacy Information Center, a research and advocacy
group for Internet privacy, asked the Federal Trade Commission to suspend the
use of facial recognition software until the government could come up with
adequate safeguards and privacy standards to protect citizens.
Mr. Brinkman said he was very excited by the possibilities of the glasses, but
acknowledged that the augmented reality glasses could pose some ethical issues.
“In addition to privacy, it’s also going to change real-world advertising, where
companies can virtually place ads over other people’s ads,” he said. “I’m really
interested in seeing how the government can successfully regulate augmented
reality in this sense. They are not really going to know what people are seeing
behind those glasses.”
Behind the Google Goggles, Virtual Reality,
NYT, 22.2.2012,
http://www.nytimes.com/2012/02/23/technology/
google-glasses-will-be-powered-by-android.html
Behold the Power of Google
January 18, 2012
2:35 pm
The New York Times
By ANDREW ROSENTHAL
The Loyal Opposition - From the Desk of Andrew Rosenthal
Talk about instant gratification.
Big Internet companies such as Google and Firefox, and the English-language
version of Wikipedia, are holding a one-day protest today against anti-piracy
bills moving through Congress. Many people (including the members of the Times
editorial board) have been fighting these bills for months, without much visible
success. But within hours of the black bar appearing on Google’s home page, D.C.
reacted.
Marco Rubio of Florida started things off. He announced this morning that he was
no longer backing the Protect Intellectual Property Act. This was interesting
not just because he’s a right-wing favorite who is talked about as White House
material, but because Senator Rubio actually co-sponsored that bill.
Later, Senator John Cornyn of Texas also said he would no longer back the bill
and said Congress should slow down on this sweeping legislation. He said on his
Facebook page that it was better to get this bill right, rather than “fast and
wrong.” That was refreshing because I can’t remember the last time Mr. Cornyn
acted sensibly. His voice matters, because he heads the Senate campaign
committee, which controls millions of dollars in re-election funds.
Congress should certainly take more time on the Senate bill, and on the House
version, the Stop Online Piracy Act, but it shouldn’t abandon the issue
entirely.
There’s a lot of hysteria on both sides of this debate. The current legislation
does go too far, and could cause real harm to free speech and innovation on the
Web. It would give copyright holders too much power, allowing Internet service
providers to block sites that seem to enable intellectual property infringement,
without legal oversight. But online piracy is a gigantic problem. Millions of
people routinely steal other people’s intellectual property every day without a
moment’s hesitation.
We’re written about these issues in detail on the editorial page and will have
more to say on the subject. With patience and political courage, the two sides
could find middle ground. Requiring court orders in lieu of pre-emptive strikes
against sites suspected of wrongdoing would go a long way
But the fact is, Google and Wikipedia did everyone a big service, and the swift
reaction of lawmakers was gratifying. Now, if Mr. Cornyn and Mr. Rubio would pay
as much attention to the Occupy protesters and the pain of the middle class, the
country would be even better off.
This blog post has been revised
to reflect the following
correction:
Correction: January 17, 2012
An earlier version of this post stated
that the Protect Intellectual Property
Act
is a House bill. It’s actually a Senate bill.
Behold the Power of Google, NYT, 18.1.2012,
http://loyalopposition.blogs.nytimes.com/2012/01/18/behold-the-power-of-google/
Google
Details
Electricity Output of Its Data Centers
September
8, 2011
The New York Times
By JAMES GLANZ
Google
released what was once among its most closely guarded secrets on Thursday: how
much electricity its enormous computing facilities consume.
The company said that its data centers continuously drew almost 260 million
watts — about a quarter of the output of a nuclear power plant — in order to run
Google searches, YouTube views, Gmail messaging and display ads on all those
services around the world.
Though the electricity figure may seem large, the company asserts that the world
is using less energy as a result of the billions of operations carried out in
Google data centers. Google says people should consider things like the amount
of gasoline saved when someone conducts a Google search rather than, say,
driving to the library. “They look big in the small context,” Urs Hoelzle,
Google’s senior vice president of technical infrastructure, said in an
interview.
Google says that people conduct over a billion searches a day and numerous other
downloads and queries, and it calculates that the average energy consumption for
a typical user is small, about 180 watt-hours a month, or the equivalent of
running a 60-watt light bulb for three hours. The overall electricity figure
includes all Google operations worldwide, including the energy required to run
its campuses and office parks, he added.
For years, Google maintained a wall of silence worthy of a government security
agency on how much electricity the company used — a silence that experts
speculated was used to cloak how quickly it was outstripping the competition in
the scale and sophistication of its data centers.
The electricity figures are no longer seen as a key to decoding the company’s
dominance, said Mr. Hoelzle. Google is known to have built efficient data
centers. Unlike many data-driven companies, Google designs and builds most of
its data centers from scratch, including its servers that use energy-saving
chips and software.
Noah Horowitz, senior scientist at the Natural Resources Defense Council in San
Francisco, applauded Google for releasing the figures but cautioned that despite
the advent of increasingly powerful and energy-efficient computing tools,
electricity use at data centers is still rising as every major corporation now
relies on them. He said the figures did not include the electricity drawn by the
personal computers, tablets and iPhones that use information from Google’s data
centers.
“When we hit the Google search button,” Mr. Horowitz said, “it’s not for free.”
Google also estimated that its total carbon emissions for 2010 were just under
1.5 million metric tons, with most of that attributable to carbon fuels that
provide electricity for the data centers. In part because of special
arrangements the company has made to purchase electricity from wind farms,
Google says that 25 percent of its energy is supplied by renewable fuels, and
estimates that it will reach 30 percent in 2011.
Google also released an estimate that an average search uses 0.3 watt-hours of
electricity, a figure that may be difficult for many people to understand
intuitively. But when multiplied by Google’s estimate of more than a billion
searches a day, the figure yields a somewhat surprising result: approximately
12.5 million watts of Google’s 260 million watt total can be accounted for by
searches, the company’s bread-and-butter service.
The rest is used by Google’s other services, including YouTube, whose power
consumption the company also depicted as very small.
The announcement is likely to spur further competition in an industry where
every company is already striving to appear “greener” than the next, said Dennis
Symanski, a senior data center project manager at the Electric Power Research
Institute, a nonprofit organization. At professional conferences on the topic,
Mr. Symanski said, “They’re all clamoring to get on the podium to claim that
they have the most efficient data center.”
Google Details Electricity Output of Its Data Centers,
NYT, 8.9.2011,
http://www.nytimes.com/2011/09/09/technology/google-details-electricity-output-of-its-data-centers.html
Google
targets Facebook with new social service
SAN
FRANCISCO | Tue Jun 28, 2011
3:31pm EDT
Reuters
By Alexei Oreskovic
SAN
FRANCISCO (Reuters) - Google Inc, frustrated by a string of failed attempts to
crack social networking, is taking another stab at fending off Facebook and
other hot social sites with a new service called Google Plus.
Google designed the service, unveiled on Tuesday, to tie together all of its
online properties, laying the foundation for a full-fledged social network. It
is the company's biggest foray into social networking since co-founder Larry
Page took over as chief executive in April.
Page has made social networking a top priority at the world's No. 1 Internet
search engine, whose position as the main gateway to online information could be
at risk as people spend more time on sites like Facebook and Twitter.
Google Plus, now available for testing, is structured in remarkably similar
fashion to Facebook, with profile pictures and newsfeeds forming a central core.
However, a user's friends or contacts are grouped into very specific circles of
their choosing, versus the common pool of friends typical on Facebook.
Enticing consumers to join another social networking service will not be easy,
said Rory Maher, an analyst with Hudson Square Research.
"They're going to have an uphill battle due to Facebook's network effects," said
Maher, citing the 700 million users that some research firms say are currently
on Facebook's service.
"The more users they (Facebook) get, the harder it gets for Google to steal
those," he said. But he added that Google's popularity in Web search and email
could help it gain a following.
To set its service apart from Facebook, Google is betting on what it says is a
better approach to privacy -- a hot-button issue that has burned Facebook, as
well as Google, in the past.
Central to Google Plus are the so-called "circles" of friends and acquaintances.
Users can organize contacts into different customized circles -- family members,
co-workers or college friends, say -- and share photos, videos or other
information only within those groups.
"In the online world there's this 'share box' and you type into it and you have
no idea who is going to get that, or where it's going to land, or how it's going
to embarrass you six months from now," said Google Vice President of Product
Management Bradley Horowitz.
"For us, privacy isn't buried six panels deep," he added.
Facebook, which has been criticized for confusing privacy controls, introduced a
feature last year that lets users create smaller groups of friends. Google,
without mentioning Facebook by name, said other social networking services'
attempts to create groups have been "bolt-on" efforts that do not work as well.
Google Plus will be rolled out to a limited number of users in what the company
is calling a field trial. Only those invited to join will initially be able to
use the service. Google did not say when it would be more widely available.
The service does not currently feature advertising.
LEARNING
FROM BUZZ
Google's stock has been pressured by concerns about rising spending within the
company and increasing regulatory scrutiny -- not to mention its struggles with
social networking. The U.S. Federal Trade Commission, among others, is currently
reviewing its business practices.
Its shares are down almost 20 percent this year after underperforming the market
in 2010.
To create Google Plus, the company went back to the drawing board in the wake of
several notable failures, including Google Wave and Google Buzz, a microblogging
service whose launch was marred by privacy snafus.
"We learned a lot in Buzz, and one of the things we learned is that there's a
real market opportunity for a product that addresses people's concerns around
privacy and how their information is shared," said Horowitz.
Google, with $29 billion in revenue last year, drew more than 1 billion visitors
worldwide to its websites in May, more than any other company, according to Web
analytics firm comScore. But people are spending more time on Facebook: The
average U.S. visitor spent 375 minutes on Facebook in May, compared with 231
minutes for Google.
Google Plus seems designed to make its online properties a pervasive part of the
daily online experience, rather than being spots where Web surfers occasionally
check in to search for a website or check email.
As with Facebook's service, Google Plus has a central Web page that displays an
ever-updating stream of the comments, photos and links being shared by friends
and contacts.
A toolbar across the top of most of Google's sites -- such as its main search
page, its Gmail site and its Maps site -- allows users to access their
personalized data feed. They can then contribute their own information to the
stream.
Google Plus will also offer a special video chat feature, in which up to 10
people can jump on a conference call. And Google will automatically store photos
taken on cell phones on its Internet servers, allowing a Google Plus user to
access the photos from any computer and share them.
When asked whether he expected people to switch from Facebook to Google Plus,
Google Senior Vice President of Engineering Vic Gundotra said people may decide
to use both.
"People today use multiple tools. I think what we're offering here offers some
very distinct advantages around some basic needs," he said.
(Reporting by
Alexei Oreskovic;
editing by
John Wallace and Gerald E. McCormick)
Google targets Facebook with new social service, R,
28.6.2011,
http://www.reuters.com/article/2011/06/28/us-google-idUSTRE75R4ZI20110628
Google to Unveil Service
to Let Users Stream Their Music
May 10, 2011
The New York Times
By CLAIRE CAIN MILLER
SAN FRANCISCO — Google plans to introduce its long-awaited service to allow
people to upload and store their music collections on the Web and listen to
their songs on Android phones or tablets and on computers.
The announcement of the new service, a so-called cloud-based music player, will
be made on Tuesday at Google I/O, the company’s developers conference here,
which will run through Wednesday.
The service, to be called Music Beta by Google, is similar to one introduced by
Amazon in March, although it will store considerably more music. And like
Amazon, Google does not have the cooperation of music labels, which means that
users cannot do certain things that would legally require licenses, like sharing
songs with friends and buying songs from Google.
But Google’s announcement at this time was unexpected because it has been
negotiating with the music labels for months to try to make a deal to team with
them on a cloud music service.
“A couple of major labels were not as collaborative and frankly were demanding a
set of business terms that were unreasonable and did not allow us to build a
product or a business on a sustainable business,” said Jamie Rosenberg, director
for digital content for Android. “So we’re not necessarily relying on the
partnerships that have proven difficult.”
After Amazon introduced its service, music label executives said they were
disappointed and exploring their legal options.
Neither Google’s nor Amazon’s cloud players make true many Web companies’ dream,
which is for people to be able to listen to their music whenever they want, on
any device. Ideally, Web companies would keep a copy of every song in the cloud,
creating a kind of Internet jukebox, and give users instant access to those they
own without uploading. But that would require licenses.
“This whole upload thing just seems like a significant barrier to wide consumer
adoption, because even with broadband it just takes a long time” to upload, said
David Pakman, who invests in digital media start-ups for the venture capital
firm Venrock, and helped found a similar music service, Myplay, in 1999.
But Amazon forced Google’s hand, he said. “If you’re faced with another six
months of brutal negotiations and your competitor just launched this, you just
get in the market and get a lot of users.”
Mr. Rosenberg characterized Music Beta as a first step in a broader cloud music
service and said Google hoped to continue negotiating with the record labels to
get licenses to offer other things, like a music store that sells songs or a
service that suggests new music to listeners.
For Google, the new service is a way to compete with the iPhone by giving
Android users the ability to easily use their music collections. Android users
could previously store MP3 music files on their phones but it was a cumbersome
process. Amazon’s service, Cloud Player, also works on Android phones, but
stores many fewer songs free.
Since songs stored by Google will stream from the Web, they are not always as
accessible as songs stored on iPods, because people can’t listen to them in
places without data connections, like airplanes. But Google stores copies of
recently played songs and certain songs that users choose for offline access.
The music labels have long argued that they should be paid when people listen to
songs on various devices. Google, Amazon and Apple, along with start-ups like
Spotify and the now-defunct Imeem, have struggled to strike agreements.
Apple is still expected to be working on such a service. It acquired Lala, a
cloud music service, and built a data center in North Carolina that could store
users’ music collections. It also has relationships with the labels through
iTunes.
Google and Amazon, meanwhile, say they do not need licenses to store music for
users and play songs on multiple devices because users upload the songs they
own, just as they would if they backed up their computers. “This is really a
personal storage service in the same way that you would put songs on an iPad or
you would put songs on a backup hard drive, so this service does not involve
licenses for the music industry,” Mr. Rosenberg said.
The service is invitation-only to start. Verizon Xoom owners will receive
invitations and others can sign up at music.google.com. Users download an
application to their computer and upload their music, which could take many
hours. The songs will be available on any device linked to the user’s Google
account using a mobile app or a Web-based player, as long as they support Flash,
which excludes iPhones and iPads.
Users can store 20,000 songs free, as opposed to Amazon’s service, which stores
up to 1,000 songs without charge.
The service syncs activity on different devices, so if users create playlists on
their phones, the playlists will automatically show up on their computers.
“We looked at the power of Google to deliver a compelling cloud-based service
and essentially married those technologies with what we felt was lacking in the
Android experience up until now,” Mr. Rosenberg said.
Google to Unveil Service
to Let Users Stream Their Music, R, 10.5.2011,
http://www.nytimes.com/2011/05/10/technology/10google.html
Google takes on Facebook
with latest social tweak
SAN FRANCISCO | Wed Mar 30, 2011
4:45pm EDT
Reuters
By Alexei Oreskovic
SAN FRANCISCO (Reuters) - Google Inc will begin allowing users to personally
endorse search results and Web pages, its latest attempt to stave off rival
Facebook Inc while trying to jump onboard a social networking boom.
The so-called "+1" button will start to appear alongside Google search results
for select users from Wednesday, letting people recommend specific search
results to friends and contacts by clicking on that button.
Eventually, the feature may begin to influence the ranking of search results,
though that is only under consideration. Results are now ranked via a closely
guarded algorithm.
The world's leader in Internet search is battling to maintain its share of Web
surfers' time and attention, which is increasingly getting taken up by Facebook,
Twitter and other social networks. But it has struggled to find its footing in
the nascent market.
Its last attempt to create a social network -- Buzz -- has not fared well. A
flood of complaints about how Buzz handled user privacy cast a pall over the
product. On Wednesday, Google announced it had reached a settlement with
regulators under which it agreed to independent privacy audits every two years.
With the new +1 buttons, Google aims to counter one of Facebook's most popular
features. The new feature comes nearly a year after Facebook began offering
special "Like" buttons to websites, creating a personalized recommendation
system that some analysts believe could challenge the traditional ranking
algorithms that search engines use to find online information.
A LOSING BATTLE?
Maintaining its role as the main gateway to information on the Internet is key
for Google, which generated roughly $29 billion in revenue last year --
primarily from search ads.
While Google remains the Internet search and advertising leader, Facebook is
taking a larger and larger portion of advertising dollars.
Google said that +1 recommendations will also appear in the paid ads that Google
displays alongside its search results. In its internal tests, Google found that
including the recommendations boosted the rates at which people click on the
ads, executives told Reuters in an interview on Tuesday.
Eventually, Google plans to let third-party websites feature +1 buttons directly
on their own pages, the company said.
Google's Matt Cutts, a principal engineer for search, said the +1 buttons were
part of the evolution of Google's own social search efforts, rather than a
direct response to Facebook's Like buttons.
"We always keep an eye out on what other people are doing, but for me the
compelling value is just that it's right there in the search results," said
Cutts.
Google introduced social search in 2009, and in February the company began
displaying special snippets underneath any search results that have been shared
by a person's contacts on Twitter, the popular Internet microblogging service.
Currently Google is not using +1 recommendations as a factor in how it ranks
search results -- a user only sees that a friend recommended a search result if
the result would have turned up in a search based on Google's existing ranking
criteria.
Google's Cutts said the company is evaluating whether to use +1 recommendations
as a ranking factor in the future.
To use the new recommendation system, users must create a Google Profile page.
Any +1 clicks that a person makes will be publicly visible to their network of
contacts, which is based on existing contacts in Google products such as the
company's Gmail email and its instant messaging service.
Google faced privacy criticisms last year when it launched Buzz, a social
networking messaging product that automatically revealed people's personal
contact lists to the public.
Cutts said that Google hoped to address any potential privacy concerns with the
+1 service by making it clear that any +1 tags are public.
"As long as people have that mental model, they know what to expect, they're not
surprised if they +1 something and it shows up in a different context," he said.
The feature will initially be available to a small portion of Google users in
the United States on Wednesday, and the company plans to allow other U.S. users
to sign up to try the +1 feature later in the day.
(Reporting by Alexei Oreskovic; Editing by Gary Hill)
Google takes on Facebook
with latest social tweak, R, 30.3.2011,
http://www.reuters.com/article/2011/03/30/us-google-idUSTRE72T5J720110330
Israeli Archive and Google Team Up
to Put Holocaust Stories at
Fingertips
February 12, 2011
The New York Times
By DINA KRAFT
TEL AVIV — When Google, the world’s largest search engine, joined forces with
Yad Vashem, keeper of the world’s largest Holocaust archive, the first thing one
Google employee here did was search for his grandfather’s name.
A link took the employee, Doron Avni, to a Google-operated page on the Yad
Vashem Web site showing a photograph of his grandfather, Yecheskel Fleischer,
taken in 1941 just after he was released from a Nazi-run prison in Lithuania.
Under the photograph of his grandfather, then 27, dark-eyed and gaunt, Mr. Avni
was able to type in details of his grandfather’s story. Icons on the page from
Facebook, Twitter and other social media outlets allow for immediate sharing of
the images and attached information.
“It’s a milestone that marks a new era in our ability to disseminate and bring
useful accessibility to Yad Vashem’s databases,” said Avner Shalev, chairman of
Yad Vashem, at a news conference last month at Google’s offices in central Tel
Aviv.
Yad Vashem began digitizing its holdings in the 1990s and has an extensive Web
site, but the technology of Google, and the expertise of a team of employees who
have been working on the project for three years, will make the information
easier to find in search engines.
The photographs have been scanned using optical character recognition, which
identifies any text in the pictures, making it searchable. So if Mr. Avni’s
grandfather’s name had not been listed in a document but had been inscribed on a
photograph, whether in Latin or Hebrew letters, he would still have been found.
The first stage of the Holocaust memorial’s partnership with Google includes
about 130,000 photographs in full resolution, hosted on a Google server, with
the option for users to add commentary, including historical background and
personal family stories. The long-term goal is to include Yad Vashem’s larger
archive of millions of documents, including survivor testimonials, diaries,
letters and manuscripts.
Two years ago Google and Yad Vashem began their first joint project, a YouTube
channel for viewing Holocaust survivors’ testimonials.
John Palfrey, co-director of the Berkman Center for Internet and Society at
Harvard, said that although such public-private partnerships could make
significant contributions, the private control of a public resource raised
potential conflicts.
“Down the road this altruistic project could look different,” Mr. Palfrey said
by phone from Cambridge, Mass. “I would say it’s a good thing that information
is made available to the world, but many of us worry about the central role a
company is playing in the preservation of the world’s cultural information.”
“It is about unknowns,” he said. “We don’t know where the corporate interest
might get misaligned with the public interest down the line.” For now, the
interests appear to have converged.
After viewing his grandfather’s photograph, Mr. Avni, the policy manager at
Google’s research and development center in Israel, added comments about how his
grandfather hid in the forests of Lithuania until the end of World War II, only
to be discovered by Russian soldiers who initially mistook him for a German and
wanted to kill him.
When the soldiers were presented with the same photograph, clearly identifying
him as a Jew because his shirt bore the Star of David that Nazis forced Jews to
wear, his life was spared.
“What my grandfather wanted was for the next generation to know about the
Holocaust,” Mr. Avni said. “He would have been inspired by this, to know his
message is now being communicated to so many people around the world.”
Israeli Archive and
Google Team Up to Put Holocaust Stories at Fingertips,
NYT, 12.2.2011,
http://www.nytimes.com/2011/02/13/world/middleeast/13holocaust.html
The Dirty Little Secrets of Search
February 12, 2011
The New York Times
By DAVID SEGAL
PRETEND for a moment that you are Google’s search engine.
Someone types the word “dresses” and hits enter. What will be the very first
result?
There are, of course, a lot of possibilities. Macy’s comes to mind. Maybe a
specialty chain, like J. Crew or the Gap. Perhaps a Wikipedia entry on the
history of hemlines.
O.K., how about the word “bedding”? Bed Bath & Beyond seems a candidate. Or
Wal-Mart, or perhaps the bedding section of Amazon.com.
“Area rugs”? Crate & Barrel is a possibility. Home Depot, too, and Sears, Pier 1
or any of those Web sites with “area rug” in the name, like arearugs.com.
You could imagine a dozen contenders for each of these searches. But in the last
several months, one name turned up, with uncanny regularity, in the No. 1 spot
for each and every term:
J. C. Penney.
The company bested millions of sites — and not just in searches for dresses,
bedding and area rugs. For months, it was consistently at or near the top in
searches for “skinny jeans,” “home decor,” “comforter sets,” “furniture” and
dozens of other words and phrases, from the blandly generic (“tablecloths”) to
the strangely specific (“grommet top curtains”).
This striking performance lasted for months, most crucially through the holiday
season, when there is a huge spike in online shopping. J. C. Penney even beat
out the sites of manufacturers in searches for the products of those
manufacturers. Type in “Samsonite carry on luggage,” for instance, and Penney
for months was first on the list, ahead of Samsonite.com.
With more than 1,100 stores and $17.8 billion in total revenue in 2010, Penney
is certainly a major player in American retailing. But Google’s stated goal is
to sift through every corner of the Internet and find the most important,
relevant Web sites.
Does the collective wisdom of the Web really say that Penney has the most
essential site when it comes to dresses? And bedding? And area rugs? And dozens
of other words and phrases?
The New York Times asked an expert in online search, Doug Pierce of Blue
Fountain Media in New York, to study this question, as well as Penney’s
astoundingly strong search-term performance in recent months. What he found
suggests that the digital age’s most mundane act, the Google search, often
represents layer upon layer of intrigue. And the intrigue starts in the
sprawling, subterranean world of “black hat” optimization, the dark art of
raising the profile of a Web site with methods that Google considers tantamount
to cheating.
Despite the cowboy outlaw connotations, black-hat services are not illegal, but
trafficking in them risks the wrath of Google. The company draws a pretty thick
line between techniques it considers deceptive and “white hat” approaches, which
are offered by hundreds of consulting firms and are legitimate ways to increase
a site’s visibility. Penney’s results were derived from methods on the wrong
side of that line, says Mr. Pierce. He described the optimization as the most
ambitious attempt to game Google’s search results that he has ever seen.
“Actually, it’s the most ambitious attempt I’ve ever heard of,” he said. “This
whole thing just blew me away. Especially for such a major brand. You’d think
they would have people around them that would know better.”
TO understand the strategy that kept J. C. Penney in the pole position for so
many searches, you need to know how Web sites rise to the top of Google’s
results. We’re talking, to be clear, about the “organic” results — in other
words, the ones that are not paid advertisements. In deriving organic results,
Google’s algorithm takes into account dozens of criteria, many of which the
company will not discuss.
But it has described one crucial factor in detail: links from one site to
another.
If you own a Web site, for instance, about Chinese cooking, your site’s Google
ranking will improve as other sites link to it. The more links to your site,
especially those from other Chinese cooking-related sites, the higher your
ranking. In a way, what Google is measuring is your site’s popularity by polling
the best-informed online fans of Chinese cooking and counting their links to
your site as votes of approval.
But even links that have nothing to do with Chinese cooking can bolster your
profile if your site is barnacled with enough of them. And here’s where the
strategy that aided Penney comes in. Someone paid to have thousands of links
placed on hundreds of sites scattered around the Web, all of which lead directly
to JCPenney.com.
Who is that someone? A spokeswoman for J. C. Penney, Darcie Brossart, says it
was not Penney.
“J. C. Penney did not authorize, and we were not involved with or aware of, the
posting of the links that you sent to us, as it is against our natural search
policies,” Ms. Brossart wrote in an e-mail. She added, “We are working to have
the links taken down.”
The links do not bear any fingerprints, but nothing else about them was
particularly subtle. Using an online tool called Open Site Explorer, Mr. Pierce
found 2,015 pages with phrases like “casual dresses,” “evening dresses,” “little
black dress” or “cocktail dress.” Click on any of these phrases on any of these
2,015 pages, and you are bounced directly to the main page for dresses on
JCPenney.com.
Some of the 2,015 pages are on sites related, at least nominally, to clothing.
But most are not. The phrase “black dresses” and a Penney link were tacked to
the bottom of a site called nuclear.engineeringaddict.com. “Evening dresses”
appeared on a site called casino-focus.com. “Cocktail dresses” showed up on
bulgariapropertyportal.com. ”Casual dresses” was on a site called
elistofbanks.com. “Semi-formal dresses” was pasted, rather incongruously, on
usclettermen.org.
There are links to JCPenney.com’s dresses page on sites about diseases, cameras,
cars, dogs, aluminum sheets, travel, snoring, diamond drills, bathroom tiles,
hotel furniture, online games, commodities, fishing, Adobe Flash, glass shower
doors, jokes and dentists — and the list goes on.
Some of these sites seem all but abandoned, except for the links. The greeting
at myflhomebuyer.com sounds like the saddest fortune cookie ever: “Sorry, but
you are looking for something that isn’t here.”
When you read the enormous list of sites with Penney links, the landscape of the
Internet acquires a whole new topography. It starts to seem like a city with a
few familiar, well-kept buildings, surrounded by millions of hovels kept upright
for no purpose other than the ads that are painted on their walls.
Exploiting those hovels for links is a Google no-no. The company’s guidelines
warn against using tricks to improve search engine rankings, including what it
refers to as “link schemes.” The penalty for getting caught is a pair of virtual
concrete shoes: the company sinks in Google’s results.
Often drastically. In 2006, Google announced that it had caught BMW using a
black-hat strategy to bolster the company’s German Web site, BMW.de. That site
was temporarily given what the BBC at the time called “the death penalty,”
stating that it was “removed from search results.”
BMW acknowledged that it had set up “doorway pages,” which exist just to attract
search engines and then redirect traffic to a different site. The company at the
time said it had no intention of deceiving users, adding “if Google says all
doorway pages are illegal, we have to take this into consideration.”
J. C. Penney, it seems, will not suffer the same fate. But starting Wednesday,
it was the subject of what Google calls “corrective action.”
Last week, The Times sent Google the evidence it had collected about the links
to JCPenney.com. Google promptly set up an interview with Matt Cutts, the head
of the Webspam team at Google, and a man whose every speech, blog post and
Twitter update is parsed like papal encyclicals by players in the search engine
world.
“I can confirm that this violates our guidelines,” said Mr. Cutts during an
hourlong interview on Wednesday, after looking at a list of paid links to
JCPenney.com.
He said Google had detected previous guidelines violations related to
JCPenney.com on three occasions, most recently last November. Each time, steps
were taken that reduced Penney’s search results — Mr. Cutts avoids the word
“punished” — but Google did not later “circle back” to the company to see if it
was still breaking the rules, he said.
He and his team had missed this recent campaign of paid links, which he said had
been up and running for the last three to four months.
“Do I wish our system had detected things sooner? I do,” he said. “But given the
one billion queries that Google handles each day, I think we do an amazing job.”
Mr. Cutts sounded remarkably upbeat and unperturbed during this conversation,
which was a surprise given that we were discussing a large, sustained effort to
snooker his employer. Asked about his zenlike calm, he said the company strives
not to act out of anger. You get the sense that Mr. Cutts and his colleagues are
acutely aware of the singular power they wield as judge, jury and appeals panel,
and they’re eager to project an air of maturity and judiciousness.
That said, he added, “I don’t think I could do my job well if in some sense I
was not offended by things that were bad for Google users.”
“Am I happy this happened?” he later asked. “Absolutely not. Is Google going to
take strong corrective action? We absolutely will.”
And the company did. On Wednesday evening, Google began what it calls a “manual
action” against Penney, essentially demotions specifically aimed at the company.
At 7 p.m. Eastern time on Wednesday, J. C. Penney was still the No. 1 result for
“Samsonite carry on luggage.”
Two hours later, it was at No. 71.
At 7 p.m. on Wednesday, Penney was No. 1 in searches for “living room
furniture.”
By 9 p.m., it had sunk to No. 68.
In other words, one moment Penney was the most visible online destination for
living room furniture in the country.
The next it was essentially buried.
PENNEY reacted to this instant reversal of fortune by, among other things,
firing its search engine consulting firm, SearchDex. Executives there did not
return e-mail or phone calls.
Penney also issued a statement: “We are disappointed that Google has reduced our
rankings due to this matter,” Ms. Brossart wrote, “but we will continue to work
actively to retain our high natural search position.”
She added that while the collection of links surely brought in additional
revenue, it was hardly a bonanza. Just 7 percent of JCPenney.com’s traffic comes
from clicks on organic search results, she wrote. A far bigger source of profits
this holiday season, she stated, came from partnerships with companies like
Yahoo and Time Warner, from new mobile applications and from in-store kiosks.
Search experts, however, say Penney likely reaped substantial rewards from the
paid links. If you think of Google as the entrance to the planet’s largest
shopping center, the links helped Penney appear as though it was the first and
most inviting spot in the mall, to millions and millions of online shoppers.
How valuable was that? A study last May by Daniel Ruby of Chitika, an online
advertising network of 100,000 sites, found that, on average, 34 percent of
Google’s traffic went to the No. 1 result, about twice the percentage that went
to No. 2.
The Keyword Estimator at Google puts the number of searches for “dresses” in the
United States at 11.1 million a month, an average based on 12 months of data. So
for “dresses” alone, Penney may have been attracting roughly 3.8 million visits
every month it showed up as No. 1. Exactly how many of those visits translate
into sales, and the size of each sale, only Penney would know.
But in January, the company was crowing about its online holiday sales. Kate
Coultas, a company spokeswoman, wrote to a reporter in January, “Internet sales
through jcp.com posted strong growth in December, with significant increases in
traffic and orders for the key holiday shopping periods of the week after
Thanksgiving and the week before Christmas.”
There was considerable pressure from investors for Penney to deliver strong
holiday results. It has been struggling through one of the more trying times of
its century of retailing. The $17.8 billion in revenue it reported last year is
the exact same figure it reported in 2001. It announced in January that it would
close a handful of underperforming stores, as well as two of its five call
centers and 19 outlets that sell excess catalog merchandise.
Adding to the company’s woes is the demise of its catalog business. Penney has
phased out what it called its Big Book and poured money into its Web site. But
so far, the loss of the catalog has not been offset by the expansion of the Web
site. At its peak, the catalog brought in about $4 billion in revenue. In 2009,
the site brought in $1.5 billion.
“For the last 35 years, Penney has tried to be accepted as a department store,
and during unusually good times, it does very well,” said Bernard Sosnick, an
analyst at Gilford Securities. “But in bad times, it gets punished by shoppers
who pull back after having spent aspirationally.”
MANY owners of Web sites with Penney links seem to relish their unreachability.
But there were exceptions, and they included cocaman.ch. (“Geekness — closer to
the world” is the cryptic header atop the site.) It turned out to be owned and
run by Corsin Camichel, a chatty 25-year-old I.T. security analyst in
Switzerland.
The word “dresses” appears in a small collection of links in the middle of a
largely blank Cocaman page. Asked about that link, Mr. Camichel said his records
show that it turned up on his site last April, though he said it might have been
earlier than that.
The link came through a Web site, TNX.net, which pays Mr. Camichel with TNX
points, which he then trades for links that drive traffic to his other sites,
like cookingutensils.net. He earns money when people visit that site and click
on the ads. He could also, he said, get cash from TNX. Currently, Cocaman is
home to 403 links, all of them placed there by TNX on behalf of clients.
“You do pretty well,” he wrote, referring to income from his links trading. “The
thing is, the more you invest (time and money) the better results you get. Right
now I get enough to buy myself new test devices for my Android apps (like
$150/month) with zero effort. I have to do nothing. Ads just sit there and if
people click, I make money.”
Efforts to reach TNX itself last week via e-mail were not successful.
Interviewing a purveyor of black-hat services face-to-face was a considerable
undertaking. They are a low-profile bunch. But a link-selling specialist named
Mark Stevens — who says he had nothing to do with the Penney link effort —
agreed to chat. He did so on the condition that his company not be named, a
precaution he justified by recounting what happened when the company apparently
angered Google a few months ago.
“It was my fault,” Mr. Stevens said. “I posted a job opening on a Stanford
Engineering alumni mailing list, and mentioned the name of our company and a
brief description of what we do. I think some Google employees saw it.”
In a matter of days, the company could not be found in a Google search.
“Literally, you typed the name of the company into the search box and we did not
turn up. Anywhere. You’d find us if you knew our Web address. But in terms of
search, we just disappeared.”
The company now operates under a new name and with a profile that is low even in
the building where it claims to have an office. The landlord at the building, a
gleaming, glassy midrise next to Route 101 in Redwood City, Calif., said she had
never heard of the company.
Mr. Stevens agreed to meet in mid-January for a dinner paid for by The Times.
Asked to pick a “fine restaurant” in his neighborhood, he rather cheekily
selected a modern French bistro in Palo Alto offering an eight-course prix fixe
meal for $118. Liquid nitrogen and “fairy tale pumpkin” were two of the featured
ingredients.
Mr. Stevens turned out to be a boyish-looking 31-year-old native of Singapore.
(Stevens is the name he uses for work; he says he has a Chinese last name, which
he did not share.) He speaks with a slight accent and in an animated hush, like
a man worried about eavesdroppers. He describes his works with the delighted,
mischievous grin of a sophomore who just hid a stink bomb.
“The key is to roll the campaign out slowly,” he said as he nibbled at seared
duck foie gras. “A lot of companies are in a rush. They want as many links as we
can get them as fast as possible. But Google will spot that. It will flag a Web
site that goes from zero links to a few hundred in a week.”
The hardest part about the link-selling business, he explained, is signing up
deep-pocketed mainstream clients. Lots of them, it seems, are afraid they’ll get
caught. Another difficulty is finding quality sites to post links. Whoever set
up the JCPenney.com campaign, he said, relied on some really low-rent, spammy
sites — the kind with low PageRanks, as Google calls its patented measure of a
site’s quality. The higher the PageRank, the more “Google juice” a site offers
others to which it is linked.
“The sites that TNX uses mostly have low PageRanks,” Mr. Stevens said.
Mr. Stevens said that Web site owners, or publishers, as he calls them, get a
small fee for each link, and the transaction is handled entirely over the Web.
Publishers can reject certain keywords and links — Mr. Stevens said some balked
at a lingerie link — but for the most part the system is on a kind of autopilot.
A client pays Mr. Stevens and his colleagues for links, which are then farmed
out to Web sites. Payment to publishers is handled via PayPal.
You might expect Mr. Stevens to have a certain amount of contempt for Google,
given that he spends his professional life finding ways to subvert it. But
through the evening he mentioned a few times that he’s in awe of the company,
and the quality of its search engine.
So how does he justify all his efforts to undermine that engine?
“I think we need to make a distinction between two different kinds of searches —
informational and commercial,” he said. “If you search ‘cancer,’ that’s an
informational search and on those, Google is amazing. But in commercial
searches, Google’s results are really polluted. My own personal experience says
that the guy with the biggest S.E.O. budget always ranks the highest.”
To Mr. Stevens, S.E.O. is a game, and if you’re not paying black hats, you are
losing to rivals with fewer compunctions.
WHY did Google fail to catch a campaign that had been under way for months? One,
no less, that benefited a company that Google had already taken action against
three times? And one that relied on a collection of Web sites that were not
exactly hiding their spamminess?
Mr. Cutts emphasized that there are 200 million domain names and a mere 24,000
employees at Google.
“Spammers never stop,” he said. Battling those spammers is a never-ending job,
and one that he believes Google keeps getting better and better at.
Here’s another hypothesis, this one for the conspiracy-minded. Last year,
Advertising Age obtained a Google document that listed some of its largest
advertisers, including AT&T, eBay and yes, J. C. Penney. The company, this
document said, spent $2.46 million a month on paid Google search ads — the kind
you see next to organic results.
Is it possible that Google was willing to countenance an extensive black-hat
campaign because it helped one of its larger advertisers? It’s the sort of
question that European Union officials are now studying in an investigation of
possible antitrust abuses by Google.
Investigators have been asking advertisers in Europe questions like this:
“Please explain whether and, if yes, to what extent your advertising spending
with Google has ever had an influence on your ranking in Google’s natural
search.” And: “Has Google ever mentioned to you that increasing your advertising
spending could improve your ranking in Google’s natural search?”
Asked if Penney received any breaks because of the money it has spent on ads,
Mr. Cutts said, “I’ll give a categorical denial.” He then made an impassioned
case for Google’s commitment to separating the money side of the business from
the search side. The former has zero influence on the latter, he said.
“If you asked me for the names of five people in advertising engineering, I
don’t think I could give you the names,” he said. “There is a very long history
at Google of saying ‘We are not going to worry about short-term revenue.’ ” He
added: “We rely on the trust of our users. We realize the responsibility that we
have to our users.”
He noted, too, that before The Times presented evidence of the paid links to
JCPenney.com, Google had just begun to roll out an algorithm change that had a
negative effect on Penney’s search results. (The tweak affected “how we trust
links,” Mr. Cutts said, declining to elaborate.)
True, JCPenney.com’s showing in Google searches had declined slightly by Feb. 8,
as the algorithm change began to take effect. In “comforter sets,” Penney went
from No. 1 to No. 7. In “sweater dresses,” from No. 1 to No. 10.
But the real damage to Penney’s results began when Google started that “manual
action.” The decline can be charted: On Feb. 1, the average Penney position for
59 search terms was 1.3.
On Feb. 8, when the algorithm was changing, it was 4.
By Feb. 10, it was 52.
MR. CUTTS said he did not plan to write about Penney’s situation, as he did with
BMW in 2006. Rarely, he explained, does he single out a company publicly,
because Google’s goal is to preserve the integrity of results, not to embarrass
people.
“But just because we don’t talk about it,” he said, “doesn’t mean we won’t take
strong action.”
The Dirty Little Secrets
of Search, NYT, 12.2.2011,
http://www.nytimes.com/2011/02/13/business/13search.html
Google Executive Who Was Jailed
Said He Was Part of
Facebook Campaign
in Egypt
February 7, 2011
The New York Times
By DAVID D. KIRKPATRICK and JENNIFER PRESTON
CAIRO — In a tearful, riveting live television interview only
two hours after his release from an Egyptian prison, the Google executive Wael
Ghonim acknowledged Monday that he was one of the people behind the anonymous
Facebook and YouTube campaign that helped galvanize the protest that has shaken
Egypt for the last two weeks.
Since he disappeared on Jan. 28, Mr. Ghonim, 30, has emerged as a symbol for the
protest movement’s young, digital-savvy organizers. During the interview on a
popular television show, he said he had been kidnapped and held blindfolded by
Egyptian authorities.
Afterward, hundreds of Egyptians took to Twitter and the Internet, calling on
him to become one of their new leaders.
“Please do not make me a hero,” Mr. Ghonim said in a voice trembling with
emotion, and later completely breaking down when told of the hundreds of people
who have died in clashes since the Jan. 25 protests began. “I want to express my
condolences for all the Egyptians who died.”
“We were all down there for peaceful demonstrations,” he added. “The heroes were
the ones on the street.”
Mr. Ghonim rejected the government’s assertions that the protests had been
instigated by foreigners or the Muslim Brotherhood, the banned Islamist
opposition group. “There was no Muslim Brotherhood presence in organizing these
protests,” he said. “It was all spontaneous, voluntary. Even when the Muslim
Brotherhood decided to take part it was their choice to do so. This belongs to
the Egyptian youth.”
The release of Mr. Ghonim, who oversees marketing efforts for Google in the
Middle East and North Africa, comes as the government is trying to portray Egypt
as returning to business as usual. But in the interview, Mr. Ghonim described
the experience of what he called his extralegal “kidnapping” and imprisonment to
rally the public to continue their protests. “It is a crime,” he said, “This is
what we are fighting.”
Ending the mystery over who helped begin the social media campaign that inspired
the protests, Mr. Ghonim said that he was a creator of the We are All Khaled
Said Facebook page. That page and multiple videos uploaded on YouTube about Mr.
Said, a 28-year-old Egyptian man beaten to death by the police in Alexandria on
June 6, 2010, helped to connect human rights organizers with average Egyptians
and to raise awareness about police abuse and torture.
Mr. Ghonim, an Egyptian who lives in Dubai with his wife and two children, was
not well known outside of technology and business circles in Egypt. But his
disappearance, followed by his interview Monday night on the same program where
the Nobel laureate and diplomat Mohamed ElBaradei plunged into Egyptian politics
a year ago, appeared to have quickly turned him into a national celebrity.
Mr. Ghonim, who came across as both humble and fearless, said he was grabbed by
security police officers while getting into a taxi and then taken to a location
where he was detained for 12 days, blindfolded the entire time. He said that he
was deeply worried that his family did not know where he was. He said he was not
physically harmed.
The first word of his release came when he posted this sentence in English on
his Twitter account at 7:05 p.m.:
“Freedom is a bless that deserves fighting for it.”
Google then confirmed the news. “It is a huge relief that Wael Ghonim has been
released,” the company said in a message posted on Twitter and then released in
an e-mail. “We send our best wishes to him and his family.”
Since last June, the Khaled Said Facebook page has attracted more than 473,000
members and has become a tool not only for organizing the protests but also for
providing regular updates about other cases of police abuse. But the page’s
creator remained a mystery.
“We did not know who he was,” said Aida Seif el-Dawla, a human rights advocate
and professor of psychiatry who works with El Nadeem Center for Rehabilitation
of Victims of Violence and Torture in Cairo. The center became involved in Mr.
Said’s case last June after police officials presented autopsy reports saying
that he died of asphyxiation from swallowing drugs rather than the brutal
beating witnessed by several people.
She said many young people identified with Mr. Said and were outraged by his
death and how the police had handled it. She said that there were many Facebook
pages, but that it was the page that Mr. Ghonim started that gained momentum.
“It was the most popular,” she said. “It gave a space for the young people to
interact with each other and to plan together.”
The Facebook page published cellphone photographs from the morgue showing the
horrific injuries Mr. Said had suffered, YouTube videos contrasting his smiling
face with the morgue photos and witness accounts that disputed the initial
Egyptian police version of his death. The information helped lead to prosecutors
arresting two police officers in connection with Mr. Said’s death. It also
prompted Facebook members to attend both street and silent protests several
times since last June.
In addition to his work at Google, Mr. Ghonim had served as a technology
consultant for Mr. ElBaradei’s pro-democracy campaign.
Before his family lost contact with him, Mr. Ghonim had posted an ominous
message on Twitter that troubled friends and family, raising concerns about his
whereabouts: “Pray for #Egypt. Very worried as it seems that government is
planning a war crime tomorrow against people. We are all ready to die #Jan25.”
While friends and family searched hospitals in the area for him, several human
rights activists became convinced that he was being held by the authorities for
his role in the social media efforts and for inspiring some of the young protest
organizers to use those media to help promote the protests.
Last Friday, members of the April 6 Youth Movement Facebook page, a group of
young advocates who began using Facebook in early 2008 to raise awareness about
labor strikes and human rights abuses, announced that they had designated Mr.
Ghonim their spokesman.
Habib Haddad, a Boston-based businessman and a friend of Mr. Ghonim’s, said he
spoke to Mr. Ghonim’s wife after her husband’s release on Monday. “Not sure I
ever heard someone that happy and emotional,” Mr. Haddad posted on his Twitter
account.
Mr. Ghonim was among many in Egypt who have disappeared during the revolt.
“At this point, Wael has become a symbolic figure,” said Mr. Haddad. “Moving
forward, it is going to be his personal decision if he were to embrace this
symbolic figure or not. As a friend, I care mostly about his personal safety and
his family’s safety.”
David D. Kirkpatrick reported from Cairo,
and Jennifer Preston from New
York.
Mona El-Naggar contributed reporting from Cairo,
and Christine Hauser from
New York.
Google Executive Who
Was Jailed
Said He Was Part of Facebook Campaign in Egypt, NYT, 7.2.2011,
http://www.nytimes.com/2011/02/08/world/middleeast/08google.html
Giant Step Into Travel for Google
July 1, 2010
The New York Times
By BRAD STONE and JAD MOUAWAD
New Google tools to help people search easily for flights are
now on the runway. It will be up to antitrust regulators to decide whether they
can take off.
Google said Thursday that it had agreed to acquire ITA, a 14-year-old flight
information software company, for $700 million in cash.
Google said it planned to create flight search tools on Google.com, a move that
could upset the entire $132 billion-a-year air travel industry as well as its
rival Microsoft.
The deal is another significant step by Google away from how it has
traditionally conducted business. Instead of pointing searchers to the most
relevant Web sites, the company is increasingly giving information directly to
users in categories like shopping or local services like restaurants. Providing
information on flights and fares would be a new area for the company.
With 63 percent of the American search market, Google has recently drawn
scrutiny from antitrust regulators every time it has moved into a new business.
Its acquisition of AdMob, a mobile advertising firm, won approval by the Federal
Trade Commission after an intensive six-month review, and only after a rival,
Apple, undermined possible objections by introducing a competing mobile ad
network. The government has also examined Google’s scanning of millions of
out-of-print and hard-to-find books.
Antitrust enforcers previously reviewed and approved Google’s 2007 acquisition
of Doubleclick, and were prepared to block a proposed deal with Yahoo in 2008
before Google walked away.
Eric E. Schmidt, Google’s chief executive, predicted a “significant review” of
the ITA acquisition. He told analysts and reporters Thursday in a conference
call: “We think they will spend a fair amount of time going through it, trying
to understand it, both because of size and price. We welcome that.”
Samuel R. Miller, an antitrust lawyer at Sidley Austin, said: “I would think
antitrust enforcers will take a very hard look at this. Every time Google makes
another acquisition, it only reinforces the argument that they are basically
trying to acquire other companies that may present potential competition to
their core dominance in paid search.”
Google does not compete directly with ITA, but many of its largest rivals in the
travel search market, including Microsoft, use ITA’s data.
ITA was founded in the 1990s by computer scientists from the Massachusetts
Institute of Technology. The company revolutionized the ability of consumers to
find the cheapest fares by making it easy to compare fares among airlines. It
has licensed its product widely, and customers include companies like American
Airlines and Continental Airlines. Web sites like Hotwire, Kayak, Orbitz and
Farecast, which is now part of Microsoft’s Bing search service, also use ITA’s
software.
Mr. Schmidt said that Google would honor all existing agreements and seek to add
new partners.
“Airline travel and search are a perfect opportunity for more innovation, more
investment and more interesting products,” Mr. Schmidt said. “The whole idea is
to give people more of what they want, and more information when they are
searching.”
Companies that may lobby against the deal include Microsoft, Expedia and Kayak;
reservation networks like Travelport, Sabre and Amadeus; and possibly even some
airlines. The deal has been rumored in the travel press for months.
Airlines could be concerned “how Google will present this information, how will
it appear in Google search and whether they will have to pay for the results,”
said Henry H. Harteveldt, an analyst at Forrester Research. “What airlines do
not know is whether they will have to bid to have their own Web sites listed
against the travel agencies.”
Google declined to predict what kinds of services might result from the
acquisition. In the conference call, Marissa Mayer, Google’s vice president for
search products and user experience, talked about being able to answer more
open-ended travel queries, like “Where can I get within seven hours and within
this price?”
“Travel is one of the hardest problems around, both in the way people like to
address queries and the accuracy and speed which you need to give people the
results they are looking for,” she said.
Rick Seaney, the co-founder of farecompare.com, which uses ITA’s technology,
said the deal might prompt some antitrust concerns, especially from Microsoft.
“We have got a couple of months to contemplate this,” Mr. Seaney said, citing
the expected lengthy review process. “We don’t really know what it all means
yet, other than they will continue on with their existing relationships.”
Giant Step Into
Travel for Google, NYT, 1.7.2010,
http://www.nytimes.com/2010/07/02/technology/02google.html
Bloodied by Google,
Microsoft Tries Again on Search
May 29, 2009
The New York Times
By MIGUEL HELFT
REDMOND, Wash. — Microsoft has been bloodied and repeatedly humbled in its
battle with Google in online search.
That explains why Steven A. Ballmer, the typically bullish and boisterous chief
executive of Microsoft, is speaking cautiously about his company’s latest volley
against Google — a new version of its search engine that Mr. Ballmer was
scheduled to demonstrate publicly for the first time at a technology conference
on Thursday.
“I’m optimistic that we’re taking a big first step,” Mr. Ballmer said in an
interview last week at Microsoft’s headquarters here. “And yet I want to be
realistic. We’ve got to take a lot more steps.”
There have already been many missteps. Despite investing billions of dollars in
its search engine technology over the years, Microsoft has watched Google
steadily eat away at its market share. This time it is taking a more targeted
approach, working to help searchers with specific online tasks. It will back its
latest release with one of the biggest marketing efforts in its history. And it
has come up with a new name, Bing, that will replace the confusing Live Search.
The stakes for Microsoft couldn’t be higher. Search has become the central tool
for navigating the Web, and ads tied to search results are becoming an ever more
important piece of the advertising market.
Microsoft is so eager to catch up that it bid nearly $50 billion last year to
buy Yahoo, the No. 2 search company behind Google. Mr. Ballmer is no longer
interested in buying Yahoo but still hopes the two companies will find a way to
team up to take on Google in search, and talks on a partnership are continuing.
For now, however, Microsoft is proceeding on its own. Bing represents the fruit
of more than a year of research showing that while users say they are generally
satisfied with Web search services, their behavior suggests that they often
stumble as they rely on search engines to complete tasks like deciding what
camera to buy, where to go on a trip or how to better understand their latest
medical diagnosis. Bing offers an array of new features that are aimed at
simplifying those tasks, and it will eventually expand to cover more of them.
“We are pushing beyond the way search works today,” said Yusuf Mehdi, senior
vice president of Microsoft’s online audience business group.
The most noticeable new feature in Bing is what Microsoft executives call a
table of contents, a navigation rail that allows users to refine their searches
and that changes with each query. A search for Taylor Swift, for instance, gives
users the option to quickly zero in on things like images, videos, lyrics and
tickets. A search for Elvis Presley will offer slightly different options — no
tickets, but a fan club.
In a search for Honda Civic, the top refinement is “used,” but in one for
Hyundai Sonata it is “problems,” because search data suggest that those are the
most frequent follow-up queries associated with those cars.
In many cases, Bing also extracts information from Web pages and presents it an
easy-to-digest format. A search for U.P.S. will deliver a search box to track
parcels, as well as a phone number for customer service. A search for
“Terminator Salvation” will display movie showtimes at nearby theaters.
Bing also presents more detailed results in four search categories — travel,
health, shopping and local. In browsing the shopping area for a Canon camera,
for instance, Bing extracts and displays information from reviews covering
things like image quality and size.
Bing, which will be available to the public by next Wednesday at www.bing.com,
is not alone in its evolution away from the traditional 10 blue links that
search engines have displayed for years. Google, for instance, has long blended
images, news articles and videos in search results, and recently began offering
ways to refine searches. Yahoo also presents movie times and is working to
extract information like reviews from Web pages. But with Bing, Microsoft
appears to have pushed the changes deeper and into more subject areas than its
rivals.
Whether that translates into success depends on many unknowns, including whether
Microsoft’s search results are generally as helpful as Google’s, as the
company’s executives promise.
“There are things where they are going to be superior to Google,” said Danny
Sullivan, a search expert and the editor of the SearchEngineLand blog. “But it
is not a game changer. The features are not going to instantly compel people to
switch.”
Mr. Sullivan said Microsoft’s best hope is that users begin spreading the word
to friends about the features of Bing that they like. “That can really resonate
with people,” he said. But Mr. Sullivan also cautioned that Google may be able
to quickly match anything that Microsoft has done that proves compelling with
users.
Others say Microsoft’s biggest challenge may be convincing enough users to give
Bing a try.
“There is not a perceived market problem with search that needs fixing,” said
Bryan Wiener, chief executive of 360i, a digital marketing agency. “They have a
marketing challenge in convincing consumers that there is reason to look beyond
Google.”
That is where Bing’s marketing campaign comes in. The company is planning to
spend well in excess of $100 million, making this one of its biggest campaigns
ever. When deals with partners are included, like agreements that have already
been announced with Hewlett-Packard, Dell and Verizon to give the search engine
prime placement on PCs and phones, the marketing effort reaches to several
hundred million dollars, according to people familiar with Bing’s marketing plan
who asked not to be named because its details are confidential.
In April, Microsoft accounted for 8.2 percent of searches in the United States,
a fraction of Google’s 64.2 percent, according to comScore. Yahoo’s share was
20.4 percent. Mr. Ballmer is confident that with Bing, Microsoft can begin
clawing its way back up the share rankings soon.
“I hope over the next year we’ll see small results,” Mr. Ballmer said. His
confidence mixed with a heavy dose of realism, he added: “Big as a percentage of
our share and small as a percentage, maybe, of Google’s share.”
Bloodied by Google, Microsoft Tries Again on
Search, NYT, 29.5.2009,
http://www.nytimes.com/2009/05/29/technology/companies/29soft.html
Even if God isn't watching you,
Google is
Street View is payback time for crooks and celebs
- and gives
every one else a proper sense of shame
March 27, 2009
From The Times
Frank Skinner
I've spent quite a few hours this week looking at Google
Street View, or as burglars call it, Google Online Shopping. To be fair to
burglars and other criminals, up to now they have had the thin end of the wedge
as far as CCTV and other surveillance systems are concerned so I guess they were
due some payback. Despite that, I love Google Street View.
I was so excited when I first saw my flat on there that I screamed for my
girlfriend to come and see. “Look, look,” I blustered excitedly, “it's our
flat.” She stared, over my shoulder, at the computer screen. Even without
turning to check her facial expression, I sensed that she was unimpressed. “You
mean the flat we've lived in for 18 months - the exterior view of which we can
enjoy at any time, simply by stepping outside?” she said.
“Yeah, but look,” I replied. I clicked to show her the full 360-degree panoramic
view of the flat and our street. When I turned for her reaction, she'd gone. I
felt a little deflated but consoled myself with a bracing e-walk around my
block. I'm hoping, as I become more adept with the Street View controls,
e-jogging will become an option.
I don't go with this argument that Street View is pointless because we could
just go and look at these streets for ourselves. The familiar becomes very
exciting once it appears on a screen. I get really bored watching those natural
history programmes with titles like Where the Panther Walks, showing places I'll
never visit and creatures I'll never see in the wild, but, a few weeks ago, they
showed the dry-cleaners at the end of my road on telly and I was beside myself
with excitement.
Come to think of it, it wasn't dissimilar to my first Street View experience
except that this time my girlfriend's response to my shrieking and pointing at
the screen was “Oh, you mean the dry-cleaners we see about ten times a week?”
“Yeah, but not in HD,” I said indignantly.
Anyway, it seems, as far as Street View is concerned, that I'm in the minority.
There have been several complaints and some images have been removed after
protests from people unwittingly caught on camera. One man was upset to discover
he'd been photographed leaving a sex shop in Soho. Some felt this was a terrible
invasion of his privacy while others felt it served him right and that, if one
chooses to frequent such places, one should accept the risk of being seen. My
own reaction was: “Why would a man who had the time and technical ability to
browse Google Street View need to go to a sex shop? Isn't there enough porn on
the internet?”
Other images that caused consternation were a drunken man being sick on the
pavement in Shoreditch, East London, and a man being arrested in Camden, but I
like this Hogarthian side to Street View. Besides, being asked to photograph
British streets but to avoid people getting arrested or vomiting on the pavement
would be quite a tricky assignment.
These offending images were blacked out before I got to view them, which is a
great pity because I like the role reversal of someone off the telly, sitting at
home, enjoying pictures of non-celebrities being drunk, arrested or involved in
sexual shenanigans. It's not just the criminals who are getting their own back
thanks to Street View. The extreme sensitivity members of the public have shown
just because there are mundane pictures of their houses online suggests a good
deal of hypocrisy. People are very happy to look at Britney's genitals on the
internet but they don't want anyone seeing their wheelie bins.
I think this ever-growing hysteria about the invasion of privacy in Great
Britain might be a direct result of the secularisation of our society. As a
Roman Catholic, I've spent my whole life believing that my every move is being
monitored. God, after all, is the ultimate CCTV. There have been many occasions
when this sense of being watched has led me to do the right thing rather than
the easier or more pleasurable wrong one. We hate those intermittent yellow
boxes on modern roads but they do, generally speaking, cause us to drive more
safely.
Maybe, now that God doesn't feature in most people's lives, society need things
like Street View and surveillance cameras to make people behave better. I don't
suppose the citizens whose sins were exposed by Google fear they'll end up
sizzling on Satan's griddle as a result but all this fuss about images of
drunkenness, crime and lust does suggest a certain sense of shame.
Another picture that got removed was a naked toddler playing in a park. A few
years back such an image would have been seen as a symbol of joyous innocence.
Now it just reminds us of another social evil we'd rather not think about. Maybe
Street View is the mirror that society doesn't want to look into.
Sorry. I've gone a bit voice-in-the-wilderness. I'm halfway through Lent and the
fasting is starting to take its toll. Anyway, perhaps the strangest Street View
story of the week was the enforced removal of images of the House of Commons.
Surely, the people who work there couldn't have anything to be ashamed of, could
they? I hope this doesn't mean they're going to black out my souvenir tea towel.
Even if God isn't
watching you, Google is, Ts, 27.3.2009,
http://www.timesonline.co.uk/tol/comment/columnists/
frank_skinner/article5982700.ece
What the Internet is doing to our brains
Is Google Making Us Stupid?
July/August 2008
The Atlantic
by Nicholas Carr
"Dave, stop. Stop, will you? Stop, Dave. Will you stop, Dave?”
So the supercomputer HAL pleads with the implacable astronaut Dave Bowman in a
famous and weirdly poignant scene toward the end of Stanley Kubrick’s 2001: A
Space Odyssey. Bowman, having nearly been sent to a deep-space death by the
malfunctioning machine, is calmly, coldly disconnecting the memory circuits that
control its artificial “ brain. “Dave, my mind is going,” HAL says, forlornly.
“I can feel it. I can feel it.”
I can feel it, too. Over the past few years I’ve had an uncomfortable sense that
someone, or something, has been tinkering with my brain, remapping the neural
circuitry, reprogramming the memory. My mind isn’t going—so far as I can
tell—but it’s changing. I’m not thinking the way I used to think. I can feel it
most strongly when I’m reading. Immersing myself in a book or a lengthy article
used to be easy. My mind would get caught up in the narrative or the turns of
the argument, and I’d spend hours strolling through long stretches of prose.
That’s rarely the case anymore. Now my concentration often starts to drift after
two or three pages. I get fidgety, lose the thread, begin looking for something
else to do. I feel as if I’m always dragging my wayward brain back to the text.
The deep reading that used to come naturally has become a struggle.
I think I know what’s going on. For more than a decade now, I’ve been spending a
lot of time online, searching and surfing and sometimes adding to the great
databases of the Internet. The Web has been a godsend to me as a writer.
Research that once required days in the stacks or periodical rooms of libraries
can now be done in minutes. A few Google searches, some quick clicks on
hyperlinks, and I’ve got the telltale fact or pithy quote I was after. Even when
I’m not working, I’m as likely as not to be foraging in the Web’s
info-thickets’reading and writing e-mails, scanning headlines and blog posts,
watching videos and listening to podcasts, or just tripping from link to link to
link. (Unlike footnotes, to which they’re sometimes likened, hyperlinks don’t
merely point to related works; they propel you toward them.)
For me, as for others, the Net is becoming a universal medium, the conduit for
most of the information that flows through my eyes and ears and into my mind.
The advantages of having immediate access to such an incredibly rich store of
information are many, and they’ve been widely described and duly applauded. “The
perfect recall of silicon memory,” Wired’s Clive Thompson has written, “can be
an enormous boon to thinking.” But that boon comes at a price. As the media
theorist Marshall McLuhan pointed out in the 1960s, media are not just passive
channels of information. They supply the stuff of thought, but they also shape
the process of thought. And what the Net seems to be doing is chipping away my
capacity for concentration and contemplation. My mind now expects to take in
information the way the Net distributes it: in a swiftly moving stream of
particles. Once I was a scuba diver in the sea of words. Now I zip along the
surface like a guy on a Jet Ski.
I’m not the only one. When I mention my troubles with reading to friends and
acquaintances—literary types, most of them—many say they’re having similar
experiences. The more they use the Web, the more they have to fight to stay
focused on long pieces of writing. Some of the bloggers I follow have also begun
mentioning the phenomenon. Scott Karp, who writes a blog about online media,
recently confessed that he has stopped reading books altogether. “I was a lit
major in college, and used to be [a] voracious book reader,” he wrote. “What
happened?” He speculates on the answer: “What if I do all my reading on the web
not so much because the way I read has changed, i.e. I’m just seeking
convenience, but because the way I THINK has changed?”
Bruce Friedman, who blogs regularly about the use of computers in medicine, also
has described how the Internet has altered his mental habits. “I now have almost
totally lost the ability to read and absorb a longish article on the web or in
print,” he wrote earlier this year. A pathologist who has long been on the
faculty of the University of Michigan Medical School, Friedman elaborated on his
comment in a telephone conversation with me. His thinking, he said, has taken on
a “staccato” quality, reflecting the way he quickly scans short passages of text
from many sources online. “I can’t read War and Peace anymore,” he admitted.
“I’ve lost the ability to do that. Even a blog post of more than three or four
paragraphs is too much to absorb. I skim it.”
Anecdotes alone don’t prove much. And we still await the long-term neurological
and psychological experiments that will provide a definitive picture of how
Internet use affects cognition. But a recently published study of online
research habits , conducted by scholars from University College London, suggests
that we may well be in the midst of a sea change in the way we read and think.
As part of the five-year research program, the scholars examined computer logs
documenting the behavior of visitors to two popular research sites, one operated
by the British Library and one by a U.K. educational consortium, that provide
access to journal articles, e-books, and other sources of written information.
They found that people using the sites exhibited “a form of skimming activity,”
hopping from one source to another and rarely returning to any source they’d
already visited. They typically read no more than one or two pages of an article
or book before they would “bounce” out to another site. Sometimes they’d save a
long article, but there’s no evidence that they ever went back and actually read
it. The authors of the study report:
It is clear that users are not reading online in the traditional sense; indeed
there are signs that new forms of “reading” are emerging as users “power browse”
horizontally through titles, contents pages and abstracts going for quick wins.
It almost seems that they go online to avoid reading in the traditional sense.
Thanks to the ubiquity of text on the Internet, not to mention the popularity of
text-messaging on cell phones, we may well be reading more today than we did in
the 1970s or 1980s, when television was our medium of choice. But it’s a
different kind of reading, and behind it lies a different kind of
thinking—perhaps even a new sense of the self. “We are not only what we read,”
says Maryanne Wolf, a developmental psychologist at Tufts University and the
author of Proust and the Squid: The Story and Science of the Reading Brain. “We
are how we read.” Wolf worries that the style of reading promoted by the Net, a
style that puts “efficiency” and “immediacy” above all else, may be weakening
our capacity for the kind of deep reading that emerged when an earlier
technology, the printing press, made long and complex works of prose
commonplace. When we read online, she says, we tend to become “mere decoders of
information.” Our ability to interpret text, to make the rich mental connections
that form when we read deeply and without distraction, remains largely
disengaged.
Reading, explains Wolf, is not an instinctive skill for human beings. It’s not
etched into our genes the way speech is. We have to teach our minds how to
translate the symbolic characters we see into the language we understand. And
the media or other technologies we use in learning and practicing the craft of
reading play an important part in shaping the neural circuits inside our brains.
Experiments demonstrate that readers of ideograms, such as the Chinese, develop
a mental circuitry for reading that is very different from the circuitry found
in those of us whose written language employs an alphabet. The variations extend
across many regions of the brain, including those that govern such essential
cognitive functions as memory and the interpretation of visual and auditory
stimuli. We can expect as well that the circuits woven by our use of the Net
will be different from those woven by our reading of books and other printed
works.
Sometime in 1882, Friedrich Nietzsche bought a typewriter—a Malling-Hansen
Writing Ball, to be precise. His vision was failing, and keeping his eyes
focused on a page had become exhausting and painful, often bringing on crushing
headaches. He had been forced to curtail his writing, and he feared that he
would soon have to give it up. The typewriter rescued him, at least for a time.
Once he had mastered touch-typing, he was able to write with his eyes closed,
using only the tips of his fingers. Words could once again flow from his mind to
the page.
But the machine had a subtler effect on his work. One of Nietzsche’s friends, a
composer, noticed a change in the style of his writing. His already terse prose
had become even tighter, more telegraphic. “Perhaps you will through this
instrument even take to a new idiom,” the friend wrote in a letter, noting that,
in his own work, his “‘thoughts’ in music and language often depend on the
quality of pen and paper.”
“You are right,” Nietzsche replied, “our writing equipment
takes part in the forming of our thoughts.” Under the sway of the machine,
writes the German media scholar Friedrich A. Kittler , Nietzsche’s prose
“changed from arguments to aphorisms, from thoughts to puns, from rhetoric to
telegram style.”
The human brain is almost infinitely malleable. People used to think that our
mental meshwork, the dense connections formed among the 100 billion or so
neurons inside our skulls, was largely fixed by the time we reached adulthood.
But brain researchers have discovered that that’s not the case. James Olds, a
professor of neuroscience who directs the Krasnow Institute for Advanced Study
at George Mason University, says that even the adult mind “is very plastic.”
Nerve cells routinely break old connections and form new ones. “The brain,”
according to Olds, “has the ability to reprogram itself on the fly, altering the
way it functions.”
As we use what the sociologist Daniel Bell has called our “intellectual
technologies”—the tools that extend our mental rather than our physical
capacities—we inevitably begin to take on the qualities of those technologies.
The mechanical clock, which came into common use in the 14th century, provides a
compelling example. In Technics and Civilization, the historian and cultural
critic Lewis Mumford described how the clock “disassociated time from human
events and helped create the belief in an independent world of mathematically
measurable sequences.” The “abstract framework of divided time” became “the
point of reference for both action and thought.”
The clock’s methodical ticking helped bring into being the scientific mind and
the scientific man. But it also took something away. As the late MIT computer
scientist Joseph Weizenbaum observed in his 1976 book, Computer Power and Human
Reason: From Judgment to Calculation, the conception of the world that emerged
from the widespread use of timekeeping instruments “remains an impoverished
version of the older one, for it rests on a rejection of those direct
experiences that formed the basis for, and indeed constituted, the old reality.”
In deciding when to eat, to work, to sleep, to rise, we stopped listening to our
senses and started obeying the clock.
The process of adapting to new intellectual technologies is reflected in the
changing metaphors we use to explain ourselves to ourselves. When the mechanical
clock arrived, people began thinking of their brains as operating “like
clockwork.” Today, in the age of software, we have come to think of them as
operating “like computers.” But the changes, neuroscience tells us, go much
deeper than metaphor. Thanks to our brain’s plasticity, the adaptation occurs
also at a biological level.
The Internet promises to have particularly far-reaching effects on cognition. In
a paper published in 1936, the British mathematician Alan Turing proved that a
digital computer, which at the time existed only as a theoretical machine, could
be programmed to perform the function of any other information-processing
device. And that’s what we’re seeing today. The Internet, an immeasurably
powerful computing system, is subsuming most of our other intellectual
technologies. It’s becoming our map and our clock, our printing press and our
typewriter, our calculator and our telephone, and our radio and TV.
When the Net absorbs a medium, that medium is re-created in the Net’s image. It
injects the medium’s content with hyperlinks, blinking ads, and other digital
gewgaws, and it surrounds the content with the content of all the other media it
has absorbed. A new e-mail message, for instance, may announce its arrival as
we’re glancing over the latest headlines at a newspaper’s site. The result is to
scatter our attention and diffuse our concentration.
The Net’s influence doesn’t end at the edges of a computer screen, either. As
people’s minds become attuned to the crazy quilt of Internet media, traditional
media have to adapt to the audience’s new expectations. Television programs add
text crawls and pop-up ads, and magazines and newspapers shorten their articles,
introduce capsule summaries, and crowd their pages with easy-to-browse
info-snippets. When, in March of this year, TheNew York Times decided to devote
the second and third pages of every edition to article abstracts , its design
director, Tom Bodkin, explained that the “shortcuts” would give harried readers
a quick “taste” of the day’s news, sparing them the “less efficient” method of
actually turning the pages and reading the articles. Old media have little
choice but to play by the new-media rules.
Never has a communications system played so many roles in our lives—or exerted
such broad influence over our thoughts—as the Internet does today. Yet, for all
that’s been written about the Net, there’s been little consideration of how,
exactly, it’s reprogramming us. The Net’s intellectual ethic remains obscure.
About the same time that Nietzsche started using his typewriter, an earnest
young man named Frederick Winslow Taylor carried a stopwatch into the Midvale
Steel plant in Philadelphia and began a historic series of experiments aimed at
improving the efficiency of the plant’s machinists. With the approval of
Midvale’s owners, he recruited a group of factory hands, set them to work on
various metalworking machines, and recorded and timed their every movement as
well as the operations of the machines. By breaking down every job into a
sequence of small, discrete steps and then testing different ways of performing
each one, Taylor created a set of precise instructions—an “algorithm,” we might
say today—for how each worker should work. Midvale’s employees grumbled about
the strict new regime, claiming that it turned them into little more than
automatons, but the factory’s productivity soared.
More than a hundred years after the invention of the steam engine, the
Industrial Revolution had at last found its philosophy and its philosopher.
Taylor’s tight industrial choreography—his “system,” as he liked to call it—was
embraced by manufacturers throughout the country and, in time, around the world.
Seeking maximum speed, maximum efficiency, and maximum output, factory owners
used time-and-motion studies to organize their work and configure the jobs of
their workers. The goal, as Taylor defined it in his celebrated 1911 treatise,
The Principles of Scientific Management, was to identify and adopt, for every
job, the “one best method” of work and thereby to effect “the gradual
substitution of science for rule of thumb throughout the mechanic arts.” Once
his system was applied to all acts of manual labor, Taylor assured his
followers, it would bring about a restructuring not only of industry but of
society, creating a utopia of perfect efficiency. “In the past the man has been
first,” he declared; “in the future the system must be first.”
Taylor’s system is still very much with us; it remains the ethic of industrial
manufacturing. And now, thanks to the growing power that computer engineers and
software coders wield over our intellectual lives, Taylor’s ethic is beginning
to govern the realm of the mind as well. The Internet is a machine designed for
the efficient and automated collection, transmission, and manipulation of
information, and its legions of programmers are intent on finding the “one best
method”—the perfect algorithm—to carry out every mental movement of what we’ve
come to describe as “knowledge work.”
Google’s headquarters, in Mountain View, California—the Googleplex—is the
Internet’s high church, and the religion practiced inside its walls is
Taylorism. Google, says its chief executive, Eric Schmidt, is “a company that’s
founded around the science of measurement,” and it is striving to “systematize
everything” it does. Drawing on the terabytes of behavioral data it collects
through its search engine and other sites, it carries out thousands of
experiments a day, according to the Harvard Business Review, and it uses the
results to refine the algorithms that increasingly control how people find
information and extract meaning from it. What Taylor did for the work of the
hand, Google is doing for the work of the mind.
The company has declared that its mission is “to organize the world’s
information and make it universally accessible and useful.” It seeks to develop
“the perfect search engine,” which it defines as something that “understands
exactly what you mean and gives you back exactly what you want.” In Google’s
view, information is a kind of commodity, a utilitarian resource that can be
mined and processed with industrial efficiency. The more pieces of information
we can “access” and the faster we can extract their gist, the more productive we
become as thinkers.
Where does it end? Sergey Brin and Larry Page, the gifted young men who founded
Google while pursuing doctoral degrees in computer science at Stanford, speak
frequently of their desire to turn their search engine into an artificial
intelligence, a HAL-like machine that might be connected directly to our brains.
“The ultimate search engine is something as smart as people—or smarter,” Page
said in a speech a few years back. “For us, working on search is a way to work
on artificial intelligence.” In a 2004 interview with Newsweek, Brin said,
“Certainly if you had all the world’s information directly attached to your
brain, or an artificial brain that was smarter than your brain, you’d be better
off.” Last year, Page told a convention of scientists that Google is “really
trying to build artificial intelligence and to do it on a large scale.”
Such an ambition is a natural one, even an admirable one, for a pair of math
whizzes with vast quantities of cash at their disposal and a small army of
computer scientists in their employ. A fundamentally scientific enterprise,
Google is motivated by a desire to use technology, in Eric Schmidt’s words, “to
solve problems that have never been solved before,” and artificial intelligence
is the hardest problem out there. Why wouldn’t Brin and Page want to be the ones
to crack it?
Still, their easy assumption that we’d all “be better off” if our brains were
supplemented, or even replaced, by an artificial intelligence is unsettling. It
suggests a belief that intelligence is the output of a mechanical process, a
series of discrete steps that can be isolated, measured, and optimized. In
Google’s world, the world we enter when we go online, there’s little place for
the fuzziness of contemplation. Ambiguity is not an opening for insight but a
bug to be fixed. The human brain is just an outdated computer that needs a
faster processor and a bigger hard drive.
The idea that our minds should operate as high-speed data-processing machines is
not only built into the workings of the Internet, it is the network’s reigning
business model as well. The faster we surf across the Web—the more links we
click and pages we view—the more opportunities Google and other companies gain
to collect information about us and to feed us advertisements. Most of the
proprietors of the commercial Internet have a financial stake in collecting the
crumbs of data we leave behind as we flit from link to link—the more crumbs, the
better. The last thing these companies want is to encourage leisurely reading or
slow, concentrated thought. It’s in their economic interest to drive us to
distraction.
Maybe I’m just a worrywart. Just as there’s a tendency to glorify technological
progress, there’s a countertendency to expect the worst of every new tool or
machine. In Plato’s Phaedrus, Socrates bemoaned the development of writing. He
feared that, as people came to rely on the written word as a substitute for the
knowledge they used to carry inside their heads, they would, in the words of one
of the dialogue’s characters, “cease to exercise their memory and become
forgetful.” And because they would be able to “receive a quantity of information
without proper instruction,” they would “be thought very knowledgeable when they
are for the most part quite ignorant.” They would be “filled with the conceit of
wisdom instead of real wisdom.” Socrates wasn’t wrong—the new technology did
often have the effects he feared—but he was shortsighted. He couldn’t foresee
the many ways that writing and reading would serve to spread information, spur
fresh ideas, and expand human knowledge (if not wisdom).
The arrival of Gutenberg’s printing press, in the 15th century, set off another
round of teeth gnashing. The Italian humanist Hieronimo Squarciafico worried
that the easy availability of books would lead to intellectual laziness, making
men “less studious” and weakening their minds. Others argued that cheaply
printed books and broadsheets would undermine religious authority, demean the
work of scholars and scribes, and spread sedition and debauchery. As New York
University professor Clay Shirky notes, “Most of the arguments made against the
printing press were correct, even prescient.” But, again, the doomsayers were
unable to imagine the myriad blessings that the printed word would deliver.
So, yes, you should be skeptical of my skepticism. Perhaps those who dismiss
critics of the Internet as Luddites or nostalgists will be proved correct, and
from our hyperactive, data-stoked minds will spring a golden age of intellectual
discovery and universal wisdom. Then again, the Net isn’t the alphabet, and
although it may replace the printing press, it produces something altogether
different. The kind of deep reading that a sequence of printed pages promotes is
valuable not just for the knowledge we acquire from the author’s words but for
the intellectual vibrations those words set off within our own minds. In the
quiet spaces opened up by the sustained, undistracted reading of a book, or by
any other act of contemplation, for that matter, we make our own associations,
draw our own inferences and analogies, foster our own ideas. Deep reading, as
Maryanne Wolf argues, is indistinguishable from deep thinking.
If we lose those quiet spaces, or fill them up with “content,” we will sacrifice
something important not only in our selves but in our culture. In a recent
essay, the playwright Richard Foreman eloquently described what’s at stake:
I come from a tradition of Western culture, in which the ideal
(my ideal) was the complex, dense and “cathedral-like” structure of the highly
educated and articulate personality—a man or woman who carried inside themselves
a personally constructed and unique version of the entire heritage of the West.
[But now] I see within us all (myself included) the replacement of complex inner
density with a new kind of self—evolving under the pressure of information
overload and the technology of the “instantly available.”
As we are drained of our “inner repertory of dense cultural inheritance,”
Foreman concluded, we risk turning into “‘pancake people’—spread wide and thin
as we connect with that vast network of information accessed by the mere touch
of a button.”
I’m haunted by that scene in 2001. What makes it so poignant, and so weird, is
the computer’s emotional response to the disassembly of its mind: its despair as
one circuit after another goes dark, its childlike pleading with the
astronaut—“I can feel it. I can feel it. I’m afraid”—and its final reversion to
what can only be called a state of innocence. HAL’s outpouring of feeling
contrasts with the emotionlessness that characterizes the human figures in the
film, who go about their business with an almost robotic efficiency. Their
thoughts and actions feel scripted, as if they’re following the steps of an
algorithm. In the world of 2001, people have become so machinelike that the most
human character turns out to be a machine. That’s the essence of Kubrick’s dark
prophecy: as we come to rely on computers to mediate our understanding of the
world, it is our own intelligence that flattens into artificial intelligence.
Is Google Making Us
Stupid?, The Altlantic, July/August 2008,
http://www.theatlantic.com/doc/200807/google
Google's
Growth
Makes Privacy Advocates Wary
November 3,
2008
Filed at 11:03 a.m. ET
The New York Times
By THE ASSOCIATED PRESS
NEW YORK
(AP) -- Perhaps the biggest threat to Google Inc.'s increasing dominance of
Internet search and advertising is the rising fear, justified or not, that
Google's broadening reach is giving it unchecked power.
This scrutiny goes deeper than the skeptical eye that lawmakers and the Justice
Department have given to Google's proposed ad partnership with Yahoo Inc. Many
objections to that deal are financial, and surround whether Google and Yahoo
could unfairly drive up online ad prices.
A bigger long-term concern for Google could be criticisms over something less
tangible -- privacy. Increasingly, as Google burrows deeper into everyday
computing, its product announcements are prompting questions about its ability
to gather more potentially sensitive personal information from users.
Why does Google log the details of search queries for so long? What does it do
with the information? Does it combine data from the search engine with
information it collects through other avenues -- such as its recently released
Web browser, Chrome?
Data gathered through most of the company's services ''disappears into a black
hole once it hits the Googleplex,'' said Simon Davies, director of London-based
Privacy International, referring to Google's headquarters. ''It's impossible to
track that information.''
Google -- whose corporate motto is ''Don't Be Evil'' -- generally sees such
concerns as misinformed. For instance, the company says it stores the queries
made through its popular search engine primarily so it can improve the service.
But whether the criticisms are valid or not, they are likely indicative of the
battles Google will face as it, like Microsoft Corp. in the 1990s, moves from
world-wowing startup to the heart of the technology establishment.
The September release of Chrome illuminated the budding conflicts.
To Google, the new browser is a platform on which future Web-based software
applications might run most efficiently. It also is a sign that Google
understands its growing power, since launching a browser is a direct challenge
to Microsoft.
In other circles, Chrome provoked suspicion. One group, Santa Monica,
Calif.-based Consumer Watchdog, argues that the browser crosses a new line.
In a mid-October letter to Google directors, Consumer Watchdog said it had
''serious privacy concerns'' about the browser and the transfer of users' data
through Google's services without giving people what it sees as ''appropriate
transparency and control.''
One of Consumer Watchdog's complaints surrounds Chrome's navigation bar, which
can be used to enter a Web site address or a search query. The group points out
that as users type in the navigation bar, Chrome relays their keystrokes to
Google even before they click ''Enter'' to finalize the command.
''The company is literally having this unnoticed conversation with itself about
you and your information,'' Consumer Watchdog President Jamie Court said.
This ''conversation'' stems from the ''Google Suggest'' feature, which is built
into the browser and other Google products, including its basic Internet search
engine.
''Google Suggest'' sends Google searches as you type, in hopes of anticipating
your desires. So if you're keying in ''Electoral College 2008 election,'' Google
will offer multiple search queries along the way. First you'd be given results
related to the term ''electoral,'' then ones on the Electoral College in
general, and finally you'd get links pertaining to Tuesday's presidential vote.
This is what worries Consumer Watchdog: Say you key in something that could be
embarrassing or deeply personal, but reconsider before you press ''Enter.'' The
autosuggest feature still sends this phrase to Google's servers, tied to your
computer's numeric Internet Protocol (IP) address.
Brian Rakowski, the product manager for Chrome, said Consumer Watchdog's fears
stemmed from confusion about the role a Google Web browser plays.
''There was some concern that, given a very naive way of how browsers work, you
may think, `Now I'm using a Google browser -- Google must know everything on
their servers about me,''' he said.
Rakowski said queries sent to Google through the autosuggest feature do include
data like a user's IP address and the time at which the queries were made. But
Google logs just 2 percent of the information brought in through ''Google
Suggest,'' in order to improve the feature, Rakowski said, and anonymizes this
data within 24 hours. The anonymization is accomplished by stripping off the
last four digits of the IP address associated with the query.
''You're flying blind without that information, so we have to collect a little
bit,'' he said. ''But we're really (collecting) the bare minimum we can to
provide that service.''
The autosuggest function can be shut off in the browser or when using Google's
search engine through its home page, but it is not immediately evident how to do
so.
One way is through Chrome's ''incognito'' tab, which turns off the autosuggest
feature and lets users surf the Web without revealing their activities to people
who have access to the same computer. However, Consumer Watchdog objects to the
design of ''incognito.'' The group claims the feature makes users feel that
their Web surfing is totally private, while in fact Google is still sending some
information back and forth between users' PCs and the company's servers.
Google takes issue with that complaint, too. The ''incognito'' function lets
users surf without leaving a trail of pages visited or ''cookie'' data-tracking
files behind, but can't entirely cloak someone's Internet activity from the
outside world.
''We try to be very upfront with users when they enter this mode about what it
provides and what it doesn't provide,'' Rakowski said.
Although Chrome is new, Consumer Watchdog is not waiting to see whether it gets
too little use to worry about. In October, Court's group wrote U.S. Attorney
General Michael Mukasey to caution him about Google's plans to sell ads for
Yahoo, saying that its fears about Google's market power have been exacerbated
by Chrome's release.
''It's about having a monopoly over our personal information, which, if it falls
into the wrong hands, could be used in a very dangerous way against us,'' Court
said.
Google's senior product counsel, Michael Yang, said the company is not using any
data from Chrome to make improvements to its ad services.
But that doesn't mollify privacy critics, who fear Google might start doing that
someday to best capitalize on its vast audience. Some 650 million people use
Google's search engine and panoply of Web services.
''The way Google has fashioned Chrome, it's a digital Trojan horse to collect
even more masses of consumer data for Google's digital advertising business,''
said Jeff Chester, executive director for the Center for Digital Democracy, a
consumer rights organization.
For now, at least, Google is planning to adopt just one change suggested by
Consumer Watchdog. When users spell a Web site's address incorrectly, Chrome
sends a request to Google to help determine the actual site the user is trying
to visit. This happens even when users are surfing ''incognito,'' and Rakowski
said it was an oversight.
''It's something we're prioritizing now that we want to fix,'' he said.
This is not to say that Google is avoiding other privacy-related changes. In
July, the company began linking to its privacy policy on its home page. It also
recently began its anonymization of the data it stores through the ''Google
Suggest'' feature.
But one other privacy-related move might say more about how Google is perceived
than anything.
In September, to placate European Union data protection officials, Google said
it would maintain its search logs -- which track search queries and the IP
addresses they came from -- for nine months instead of 18, as it had been doing.
After that time, Google will alter IP addresses to mask their source. (That
probably won't provide true anonymity, since an aggregated list of search
queries over time will likely reveal clues about who made them.)
Google hoped the move would win it favor. After all, Microsoft waits 18 months
before it anonymizes its search engine logs, and Yahoo does so after 13.
Even so, the EU's justice and home affairs commissioner said Google should
shorten its logs further, to six months. Davies, of Privacy International, says
the change from 18 to nine months was ''not meaningful.''
Court says that with all its products, Google has more opportunities than its
peers to capture personal information without users realizing it.
''Google's founders may say, `We're going to protect that information,' but no
other company,'' he said, ''is positioned to exploit that information in the way
Google is.''
Google's Growth Makes Privacy Advocates Wary, NYT,
3.11.2008,
http://www.nytimes.com/aponline/business/AP-TEC-Google-Privacy.html
Google
to Digitize Newspaper Archives
September
9, 2008
The New York Times
By MIGUEL HELFT
SAN
FRANCISCO — Google has begun scanning microfilm from some newspapers’ historic
archives to make them searchable online, first through Google News and
eventually on the papers’ own Web sites, the company said Monday.
The new program expands a two-year-old service that allows Google News users to
search the archives of some major newspapers and magazines, including The New
York Times, The Washington Post and Time, that were already available in digital
form. Readers will be able to search the archives using keywords and view
articles as they appeared originally in the print pages of newspapers.
Under the expanded program, Google will shoulder the cost of digitizing
newspaper archives, much as the company does with its book-scanning project.
Google angered some book publishers because it had failed to seek permission to
scan books that were protected by copyrights. It will obtain permission from
newspaper publishers before scanning their archives.
Google, based in Mountain View, Calif., will place advertisements alongside
search results, and share the revenue from those ads with newspaper publishers.
Initially, the archives will be available through Google News, but the company
plans to give newspapers a way to make their archives available on their own
sites.
“This is really good for newspapers because we are going to be bringing online
an old generation of contributions from journalists, as well as widening the
reader base of news archives,” said Marissa Mayer, vice president for search
products and user experience at Google.
But many newspaper publishers view search engines like Google as threats to
their own business. Many of them also see their archives as a potential source
of revenue, and it is not clear whether they will willingly hand them over to
Google.
“The concern is that Google, in making all of the past newspaper content
available, can greatly commoditize that content, just like news portals have
commoditized current news content,” said Ken Doctor, an analyst with Outsell, a
research company.
Google said it was working with more than 100 newspapers and with partners like
Heritage Microfilm and ProQuest, which aggregate historical newspaper archives
in microfilm. It has already scanned millions of articles.
Other companies are already working with newspapers to digitize archives and
some sell those archives to schools, libraries and other institutions, helping
newspapers earn money from their historical content.
The National Digital Newspaper Program, a joint program of the National
Endowment for the Humanities and the Library of Congress, is creating a digital
archive of historically significant newspapers published in the United States
from 1836 to 1922. It will be freely accessible on the Internet.
Newspapers that are participating in the Google program say it is attractive.
“We wouldn’t be talking about digitization if Google had not entered this
arena,” said Tim Rozgonyi, research editor at The St. Petersburg Times. “We
looked into it years back, and it appeared to be exceedingly costly.”
Mr. Rozgonyi said that the newspaper might be able to generate additional
revenue from the digital archives by producing historical booklets or
commemorative front pages. But he said that increasing sales was not the primary
objective of the digitization program.
“Getting the digitized content available is a wonderful thing for people of this
area,” he said. “They’ll be able to go to our site or Google’s and tap into 100
years of history.”
Pierre Little, publisher of The Quebec Chronicle-Telegraph, which has been
published since 1764 and calls itself “North America’s Oldest Newspaper,” said
many readers visit the newspaper’s Web site to look for obituaries and conduct
research on their ancestors.
“We could envision that thousands of families would be attracted to our archives
to search for people who came over to the New World,” Mr. Little said. “We hope
that will be a financial windfall for us.”
Brad Stone contributed reporting.
Google to Digitize Newspaper Archives, NYT, 9.9.2008,
http://www.nytimes.com/2008/09/09/technology/09google.html
Google
At Age 10
September
4, 2008, 7:36 pm
The New York Times
By Miguel Helft
Google
applied for incorporation as a business 10 years ago Thursday, according to a
timeline supplied by the company. The application was accepted on Sept. 7, which
is Sunday.
In that decade, the search engine company has quickly emerged as the most
successful business on the Web, and many expect it to dominate the next era of
computing as thoroughly as Microsoft dominated the era of personal computers.
Here’s a quick snapshot of Google by the numbers along with some comparisons to
Microsoft. The sources of the data are the companies, Yahoo Finance and
comScore.
Google’s age: 10
Microsoft’s age: 33
Google’s revenue in the last 4 quarters: $19.6 billion
Microsoft’s revenue in the last 4 quarters: $60.4 billion
Microsoft’s revenue at age 10: $140 million
($279 million in today’s dollars)
Google’s revenue per hour in the last 4 quarters: $2.2 million
Microsoft’s revenue per hour in the last 4 quarters: $6.9 million
Google net income in the last 4 quarters: $4.85 billion
Microsoft’s net income in the last 4 quarters: $17.6 billion
Google employees, as of June 30th: 19,604
Microsoft employees, as of May 31st: 89,809
Google’s revenue per employee: $1 million
Microsoft revenue per employee: $672,000
Market value of Google: $142 billion
Market value of Microsoft: $241 billion
Number of tech companies with a market value larger than Google’s: 3 (Microsoft,
IBM and Apple, in that order)
Worldwide searches on Google in July: 48.7 billion
Worldwide searches on Microsoft in July: 2.3 billion
Worldwide searches per hour on Google in July: 65 million
Worldwide searches per hour on Microsoft in July: 3.1 million
Google At Age 10, NYT, 4.9.2008,
http://bits.blogs.nytimes.com/2008/09/04/google-at-age-10/
Google's
stock tops $600 for first time
8 October
2007
By Michael Liedtke, Associated Press
USA Today
SAN
FRANCISCO — Google's stock price sailed past $600 for the first time Monday,
extending a rally that has elevated the Internet search leader's market value by
about $25 billion in the past month.
The
Mountain View-based company's shares traded as high as $601.45 before slipping
back to $597.13 in morning trading. It marked the sixth time in the past 12
trading sessions that the stock has reached a new peak climbing on the lofty
expectations for Google's third-quarter earnings. The results are scheduled to
be released Oct. 18.
The latest milestone served as yet another reminder of the immense wealth
created since the company went public in August 2004.
Google shares have increased more than sevenfold from their initial public
offering price of $85, leaving the 9-year-old company with a market value of
$187 billion — worth more than bigger, more mature businesses like Wal-Mart
Stores, Coca-Cola, Hewlett-Packard. and IBM.
It took slightly more than 10 months for Google's stock to make the leap from
$500 to $600. By comparison, the journey from $400 to $500 required more than a
year to complete. The shares hurdled $300 in June 2005 after passing the $100
and $200 thresholds in 2004.
Analysts began predicting Google's stock would reach $600 at the start of 2006
when the shares were still hovering around $420. Some analysts already are
advising investors that Google's stock will hit $700 within the next year. The
average target price for the stock is $606.61 among 28 analysts polled by
Thomson Financial.
The biggest beneficiaries of Google's co-founders have been Larry Page and
Sergey Brin, who began developing a new approach to online search, then called
"BackRub," in a Stanford University dorm room in 1996. Page and Brin, both 34,
now rank among the world's wealthiest men with fortunes approaching $20 billion
apiece.
Google's chief executive, Eric Schmidt, and top sales executive, Omid
Kordestani, also have accumulated enough stock in the company to become
multibillionaires.
Hundreds of other Google employees are millionaires.
Google's stock has reigned as one of the hottest commodities on Wall Street
because its search engine has turned into a moneymaking machine as advertisers
spend more on the Internet to connect with consumers who are increasingly
shunning television, radio and traditional print media. Google's search engine
is the hub of the Web's most lucrative ad network.
If it gets its way, Google could become an even more powerful through its
proposed $3.1 billion acquisition of ad distributor DoubleClick The deal is
being held up while federal antitrust regulators review complaints that the
acquisition would give Google too much control over online ad prices and
personal information collected from consumers.
The recent enthusiasm surrounding Google's stock contrasts with the mood less
than two months ago. Dragged down by a second-quarter earnings report that
lagged analyst projections, Google's stock dipped below $500 in mid-August.
But the bulls stampeded back to Google's stock as it became more apparent the
company had widened its already formidable lead over Yahoo Inc. and Microsoft in
the battle to process the search requests that trigger revenue-generating
advertisements.
The more positive sentiment has driven a 15% increase in Google's stock since
Sept. 7. For the year, the shares have climbed by 30%, outstripping the stock
market's major indexes.
Google's stock tops $600 for first time, UT, 8.10.2007,
http://www.usatoday.com/tech/techinvestor/stocknews/
2007-10-08-google-stock_N.htm
For
Google,
Advertising and Phones
Go Together
October 8, 2007
The New York Times
By MIGUEL HELFT
SAN FRANCISCO, Oct. 7 — For more than two years, a large group
of engineers at Google has been working in secret on a mobile phone project. As
word about their efforts has trickled out, expectations in the tech world for
what has been called the Google phone, or GPhone, have risen, the way they do
for Apple loyalists ahead of a speech by Steven P. Jobs.
But the GPhone is not likely to be the second coming of the iPhone — and
Google’s goals are very different from Apple’s.
Google wants to extend its dominance of online advertising to the mobile
Internet, a small market today, but one that is expected to grow rapidly. It
hopes to persuade wireless carriers and mobile phone makers to offer phones
based on its software, according to people briefed on the project. The cost of
those phones may be partly subsidized by advertising that appears on their
screens.
Google is expected to unveil the fruit of its mobile efforts later this year,
and phones based on its technology could be available next year.
Some analysts say that the Google project’s effect on the wireless industry is
not likely to be as profound, at least initially, as that of Apple’s iPhone,
whose revolutionary look and features have redefined consumer expectations for
mobile phones.
“The iPhone was a milestone in terms of how people use a mobile device,” said
Karsten Weide, an analyst with IDC. “The GPhone, if it does come out, will help
Google with distribution for their online services.”
At the core of Google’s phone efforts is an operating system for mobile phones
that will be based on open-source Linux software, according to industry
executives familiar with the project.
In addition, Google is expected to develop mobile versions of its applications
that go well beyond the mobile search and map software it offers today. Those
applications may include a Web browser to run on cellphones.
While Google has built phone prototypes to test its software and show off its
technology to manufacturers, the company is not likely to make the phones
itself, according to analysts.
In short, Google is not creating a gadget to rival the iPhone, but rather
creating software that will be an alternative to Windows Mobile from Microsoft
and other operating systems, which are built into phones sold by many
manufacturers. And unlike Microsoft, Google is not expected to charge phone
makers a licensing fee for the software.
“The essential point is that Google’s strategy is to lead the creation of an
open-source competitor to Windows Mobile,” said one industry executive, who did
not want his name used because his company has had contacts with Google. “They
will put it in the open-source world and take the economics out of the Windows
Mobile business.”
Some believe another major goal of the phone project is to loosen the control of
carriers over the software and services that are available on their networks.
“Google’s agenda is to disaggregate carriers,” said Dan Olschwang, the chief
executive of JumpTap, a start-up that provides search and advertising services
to several mobile phone operators.
Google declined to comment on any specifics of its mobile phone initiative. But
its chief executive, Eric E. Schmidt, has said several times that the cellphone
market presented the largest growth opportunity for Google. “We have a large
investment in mobile phones and mobile phone platform applications,” Mr. Schmidt
said in an interview this year.
Industry analysts say that Google, which has little experience with complex
hardware, faces significant challenges.
“Running a Web site and a search engine is one thing,” said Mr. Weide of IDC.
“But developing a phone is a whole different game. It will not be easy for
them.”
Mr. Weide added that Google’s impact on the industry will depend to a large
extent on its ability to sign deals with wireless carriers that distribute
hundreds of millions of phones each year and often control what software and
services run on them.
Some carriers, especially in the United States, are likely to give Google a cool
reception. Companies like Verizon Wireless and AT&T have spent billions of
dollars building and upgrading their networks, establishing relationships with
customers, subsidizing handsets and creating their own mobile Internet portals.
Now they want to make sure those investments pay off, in part, through mobile
advertising, and they see Google and other search engines, who are after the
same ad dollars, as competitors.
As a result, most carriers in the United States have chosen to shun the major
search engines for now. Instead, they have promoted the search engines and ad
systems of small technology companies like JumpTap and Medio Systems, whose
services they can stamp with their own brands.
Most carriers declined to comment on Google’s plans. But Arun Sarin, the chief
executive of Britain’s Vodafone Group, which offers the Google service on its
phones, said it was not clear what compelling functions Google would offer that
are not already available.
“What is it that is missing in life that they are going to fulfill?” Mr. Sarin
said. “It is not a no-brainer. You can reach Google already through a number of
devices. You don’t need a Google phone to do that.”
Google’s desire to loosen the carriers’ control over their networks has hardly
been a secret. The company recently lobbied the Federal Communications
Commission to impose rules on any carrier who wins a coming auction for valuable
wireless spectrum. The rules, which the F.C.C. adopted despite opposition from
Verizon and others, require that the network using a portion of that spectrum be
open to any handset and software applications from any company.
Google said it is considering bidding for some of that spectrum. But regardless
of who wins it, phones based on Google’s software would be able to take
advantage of it.
Google’s lobbying, as well as its work on a phone software platform that would
be open to other applications, represent an effort to bring to the mobile
Internet the dynamics of the PC-oriented Internet, which is free of control by
network operators. Google is hoping that it can beat competitors in an open
environment.
The mobile phone project at Google was built in part around Android, a small
mobile software company it acquired in 2005. An Android co-founder, Andy Rubin,
had founded Danger, which created the popular T-Mobile Sidekick smartphone. Mr.
Rubin works at Google’s headquarters in Mountain View, but another part of
Google’s team is reported to be in Boston, where Android’s co-founder, Rich
Miner, another veteran of the mobile phone industry, is based.
Some analysts say there are no guarantees that Google will be able to replicate
its online success in the mobile world.
“The wireless market does not have the same global scale and scope efficiencies,
nor the lack of transactional friction, of software on the Internet,” said Scott
Cleland, a telecommunications industry analyst who recently testified before the
Senate against Google’s proposed acquisition of DoubleClick.
“It is a completely different world and completely different set of economics,”
said Mr. Cleland, who has opposed Google on a number of policy issues.
Microsoft, whose mobile operating system has been available for years, has
distribution agreements with 48 handset makers and 160 carriers around the
world. Still, only 12 million phones sold this year will be based on Microsoft’s
software, giving it 10 percent of the smartphone market, according to IDC.
Microsoft declined to comment on potential competition from Google. “The market
is huge, and our partners are really motivated to bring Windows Mobile phones to
market,” said Doug Smith, director for marketing of Microsoft’s mobile
communications business.
Mahesh Veerina, the founder and chief executive of Celunite, which makes
cellphone software based on Linux, said Google’s offering was likely to be
attractive to small carriers, who may see it as a competitive weapon.
But if Google-powered phones prove to be a hit with consumers, other carriers
may feel pressure to follow suit, said Richard Doherty, director for the
Envisioneering Group, a consulting firm.
“No one wants to be the last carrier to endorse Google,” Mr. Doherty said.
Matt Richtel and Laura M. Holson contributed reporting.
For Google,
Advertising and Phones Go Together, NYT, 8.10.2007,
http://www.nytimes.com/2007/10/08/business/media/08googlephone.html
Google and I.B.M.
Join in ‘Cloud Computing’ Research
October 8, 2007
The New York Times
By STEVE LOHR
Even the nation’s elite universities do not provide the
technical training needed for the kind of powerful and highly complex computing
Google is famous for, say computer scientists. So Google and I.B.M. are
announcing today a major research initiative to address that shortcoming.
The two companies are investing to build large data centers that students can
tap into over the Internet to program and research remotely, which is called
“cloud computing.”
Both companies have a deep business interest in this new model in which
computing chores increasingly move off individual desktops and out of corporate
computer centers to be handled as services over the Internet.
Google, the Internet search giant, is the leader in this technology. But
companies like Yahoo, Amazon, eBay and Microsoft have built Internet consumer
services like search, social networking, Web e-mail and online commerce that use
cloud computing. In the corporate market, I.B.M. and others have built Internet
services to predict market trends, tailor pricing and optimize procurement and
manufacturing.
Behind these services are data centers that typically use thousands of
processors, store countless libraries of data and engage specialized software to
tackle what scientists call Internet-scale computing challenges. This new kind
of data-intensive supercomputing often involves scouring the Web and other data
sources in seconds or minutes for patterns and insights.
Most of the innovation in cloud computing has been led by corporations, but
industry executives and computer scientists say a shortage of skills and talent
could limit future growth.
“We in academia and the government labs have not kept up with the times,” said
Randal E. Bryant, dean of the computer science school at Carnegie Mellon
University. “Universities really need to get on board.”
Six universities will be involved in the initiative. They are Carnegie Mellon,
Massachusetts Institute of Technology, Stanford University, the University of
California, Berkeley, the University of Maryland and the University of
Washington.
Google is building a data center, at an undisclosed location, that will contain
more than 1,600 processors by the end of the year. I.B.M. is also setting up a
data center for the initiative.
The centers will run an open-source version of Google’s data center software,
and I.B.M. is contributing open-source tools to help students write Internet
programs and data center management software.
The data centers under way have a small fraction of the computing firepower
behind Google’s Internet search service. But they will be big enough, scientists
say, to do ambitious Internet research. Setting up and running such centers,
including providing the electricity and technical staff, is difficult and
expensive. The two companies, a person who was told of their plans said, have
committed a total of $30 million over two years for the project.
“This is a huge contribution because it allows for a type of education and
research that we can’t do today,” said Edward Lazowska, a computer science
professor at the University of Washington.
The companies’ and academics’ long-term goal is to expand the data-center
clusters so students from many schools can participate and to enlist the support
of other companies and the federal government.
The companies and university scientists involved in the initiative have talked
to the National Science Foundation and other agencies.
The collaboration began after a meeting in December between Eric E. Schmidt,
chief executive of Google, and Samuel J. Palmisano, I.B.M.’s chief executive, at
Google’s headquarters in Mountain View, Calif.
In an interview on Friday, Mr. Schmidt recalled that he had sketched out his
vision of cloud computing on a whiteboard, emphasizing its potential economic
and social importance, and urged the I.B.M. chief to cooperate to build the
skills needed.
At the time, Mr. Palmisano said, he had just come out of a day of technology
briefings at I.B.M., and his company is doing a lot of research in the same
field. I.B.M. also has deep knowledge and experience in building and managing
complex data centers.
Mr. Schmidt said, “I.B.M. has some of the best technology in the industry, and
we couldn’t have done this without them.”
Mr. Palmisano noted that cooperation between the two companies was easier
because Google is mainly a consumer company, while I.B.M. concentrates on the
corporate market. “We’re more complementary than anything else,” Mr. Palmisano
said. “We don’t really collide in the marketplace.”
And by helping university students, I.B.M. and Google hope to help themselves in
the marketplace.
“We’re trying to create the easiest possible on-ramp for universities into this
world of cloud computing,” said Stuart I. Feldman, a vice president of
engineering at Google and a former senior researcher at I.B.M. “But yes, this
kind of computing is core value to Google and I.B.M. We have an interest, no
doubt.”
Google and I.B.M.
Join in ‘Cloud Computing’ Research, NYT, 8.10.2007,
http://www.nytimes.com/2007/10/08/technology/08cloud.html
The internet
Who's afraid of
Google?
Aug 30th 2007
From The Economist print edition
The world's internet superpower faces testing times
RARELY if ever has a company risen so fast in so many ways as
Google, the world's most popular search engine. This is true by just about any
measure: the growth in its market value and revenues; the number of people
clicking in search of news, the nearest pizza parlour or a satellite image of
their neighbour's garden; the volume of its advertisers; or the number of its
lawyers and lobbyists.
Such an ascent is enough to evoke concerns—both paranoid and justified. The list
of constituencies that hate or fear Google grows by the week. Television
networks, book publishers and newspaper owners feel that Google has grown by
using their content without paying for it. Telecoms firms such as America's AT&T
and Verizon are miffed that Google prospers, in their eyes, by free-riding on
the bandwidth that they provide; and it is about to bid against them in a
forthcoming auction for radio spectrum. Many small firms hate Google because
they relied on exploiting its search formulas to win prime positions in its
rankings, but dropped to the internet's equivalent of Hades after Google tweaked
these algorithms.
And now come the politicians. Libertarians dislike Google's
deal with China's censors. Conservatives moan about its uncensored videos. But
the big new fear is to do with the privacy of its users. Google's business model
(see article) assumes that people will entrust it with ever more information
about their lives, to be stored in the company's “cloud” of remote computers.
These data begin with the logs of a user's searches (in effect, a record of his
interests) and his responses to advertisements. Often they extend to the user's
e-mail, calendar, contacts, documents, spreadsheets, photos and videos. They
could soon include even the user's medical records and precise location
(determined from his mobile phone).
More JP Morgan than Bill Gates
Google is often compared to Microsoft (another enemy,
incidentally); but its evolution is actually closer to that of the banking
industry. Just as financial institutions grew to become repositories of people's
money, and thus guardians of private information about their finances, Google is
now turning into a custodian of a far wider and more intimate range of
information about individuals. Yes, this applies also to rivals such as Yahoo!
and Microsoft. But Google, through the sheer speed with which it accumulates the
treasure of information, will be the one to test the limits of what society can
tolerate.
It does not help that Google is often seen as arrogant. Granted, this complaint
often comes from sour-grapes rivals. But many others are put off by Google's
cocksure assertion of its own holiness, as if it merited unquestioning trust.
This after all is the firm that chose “Don't be evil” as its corporate motto and
that explicitly intones that its goal is “not to make money”, as its boss, Eric
Schmidt, puts it, but “to change the world”. Its ownership structure is set up
to protect that vision.
Ironically, there is something rather cloudlike about the multiple complaints
surrounding Google. The issues are best parted into two cumuli: a set of
“public” arguments about how to regulate Google; and a set of “private” ones for
Google's managers, to do with the strategy the firm needs to get through the
coming storm. On both counts, Google—contrary to its own propaganda—is much
better judged as being just like any other “evil” money-grabbing company.
Grab the money
That is because, from the public point of view, the main
contribution of all companies to society comes from making profits, not giving
things away. Google is a good example of this. Its “goodness” stems less from
all that guff about corporate altruism than from Adam Smith's invisible hand. It
provides a service that others find very useful—namely helping people to find
information (at no charge) and letting advertisers promote their wares to those
people in a finely targeted way.
Given this, the onus of proof is with Google's would-be prosecutors to prove it
is doing something wrong. On antitrust, the price that Google charges its
advertisers is set by auction, so its monopolistic clout is limited; and it has
yet to use its dominance in one market to muscle into others in the way
Microsoft did. The same presumption of innocence goes for copyright and privacy.
Google's book-search product, for instance, arguably helps rather than hurts
publishers and authors by rescuing books from obscurity and encouraging readers
to buy copyrighted works. And, despite Big Brotherish talk about knowing what
choices people will be making tomorrow, Google has not betrayed the trust of its
users over their privacy. If anything, it has been better than its rivals in
standing up to prying governments in both America and China.
That said, conflicts of interest will become inevitable—especially with privacy.
Google in effect controls a dial that, as it sells ever more services to you,
could move in two directions. Set to one side, Google could voluntarily destroy
very quickly any user data that it collects. That would assure privacy, but it
would limit Google's profits from selling to advertisers information about what
you are doing, and make those services less useful. If the dial is set to the
other side and Google hangs on to the information, the services will be more
useful, but some dreadful intrusions into privacy could occur.
The answer, as with banks in the past, must lie somewhere in the middle; and the
right point for the dial is likely to change, as circumstances change. That will
be the main public interest in Google. But, as the bankers (and Bill Gates) can
attest, public scrutiny also creates a private challenge for Google's managers:
how should they present their case?
One obvious strategy is to allay concerns over Google's trustworthiness by
becoming more transparent and opening up more of its processes and plans to
scrutiny. But it also needs a deeper change of heart. Pretending that, just
because your founders are nice young men and you give away lots of services,
society has no right to question your motives no longer seems sensible. Google
is a capitalist tool—and a useful one. Better, surely, to face the coming storm
on that foundation, than on a trite slogan that could be your undoing.
Who's afraid of
Google?, E, 1.9.2007,
http://www.economist.com/node/9725272
Google is watching you
'Big Brother'
row
over plans for personal database
Published: 24
May 2007
The Independent
By Robert Verkaik, Law Editor
Google, the
world's biggest search engine, is setting out to create the most comprehensive
database of personal information ever assembled, one with the ability to tell
people how to run their lives.
In a mission statement that raises the spectre of an internet Big Brother to
rival Orwellian visions of the state, Google has revealed details of how it
intends to organise and control the world's information.
The company's chief executive, Eric Schmidt, said during a visit to Britain this
week: "The goal is to enable Google users to be able to ask the question such as
'What shall I do tomorrow?' and 'What job shall I take?'."
Speaking at a conference organised by Google, he said : "We are very early in
the total information we have within Google. The algorithms [software] will get
better and we will get better at personalisation."
Google's declaration of intent was publicised at the same time it emerged that
the company had also invested £2m in a human genetics firm called 23andMe. The
combination of genetic and internet profiling could prove a powerful tool in the
battle for the greater understanding of the behaviour of an online service user.
Earlier this year Google's competitor Yahoo unveiled its own search technology,
known as Project Panama, which monitors internet visitors to its site to build a
profile of their interests.
Privacy protection campaigners are concerned that the trend towards
sophisticated internet tracking and the collating of a giant database represents
a real threat, by stealth, to civil liberties.
That concern has been reinforced by Google's $3.1bn bid for DoubleClick, a
company that helps build a detailed picture of someone's behaviour by combining
its records of web searches with the information from DoubleClick's "cookies",
the software it places on users' machines to track which sites they visit.
The Independent has now learnt that the body representing Europe's data
protection watchdogs has written to Google requesting more information about its
information retention policy.
The multibillion-pound search engine has already said it plans to impose a limit
on the period it keeps personal information.
A spokesman for the Information Commissioner's Office, the UK agency responsible
for monitoring data legislation confirmed it had been part of the group of
organisations, known as the Article 29 Working Group, which had written to
Google.
It is understood the letter asked for more detail about Google's policy on the
retention of data. Google says it will respond to the Article 29 request next
month when it publishes a full response on its website.
The Information Commissioner's spokeswoman added: "I can't say what was in it
only that it was written in response to Google's announcement that will hold
information for no more than two years."
Ross Anderson, professor of Security Engineering at Cambridge University and
chairman of the Foundation for Information Policy Research, said there was a
real issue with "lock in" where Google customers find it hard to extricate
themselves from the search engine because of the interdependent linkage with
other Google services, such as iGoogle, Gmail and YouTube. He also said internet
users could no longer effectively protect their anonymity as the data left a key
signature.
"A lot of people are upset by some of this. Why should an angst-ridden teenager
who subscribes to MySpace have their information dragged up 30 years later when
they go for a job as say editor of the Financial Times? But there are serious
privacy issues as well. Under data protection laws, you can't take information,
that may have been given incidentally, and use it for another purpose. The
precise type and size of this problem is yet to be determined and will change as
Google's business changes."
A spokeswoman for the Information Commissioner said that because of the
voluntary nature of the information being targeted, the Information Commission
had no plans to take any action against the databases.
Peter Fleischer, Google's global privacy Ccunsel, said the company intended only
doing w hat its customers wanted it to do. He said Mr Schmidt was talking about
products such as iGoogle, where users volunteer to let Google use their web
histories. "This is about personalised searches, where our goal is to use
information to provide the best possible search for the user. If the user
doesn't want information held by us, then that's fine. We are not trying to
build a giant library of personalised information. All we are doing is trying to
make the best computer guess of what it is you are searching for."
Privacy protection experts have argued that law enforcement agents - in certain
circumstances - can compel search engines and internet service providers to
surrender information. One said: "The danger here is that it doesn't matter what
search engines say their policy is because it can be overridden by national
laws."
How Google
grew to dominate the internet
It's all about the algorithms. When Google first started up, in summer 1998, it
quickly made its mark by being the internet's best, most efficient search
engine. Now Google wants to know everything - all the knowledge contained on the
world wide web, and everything about you as a computer user, too.
The key, at every step of the way, has been the methodology the company has used
to catalogue and present information. The first stroke of genius that the
company's founders, Larry Page and Sergey Brin, had while they were still in
graduate school was to measure responses to an internet search not only by the
frequency of the search word but by the number of times a given web page was
accessed via other web pages. It was a revolutionary idea at the time, now
copied by every one of their rivals.
A decade later, their technical brilliance is operating on an altogether more
ambitious scale. Google is now a $150bn (£77bn) company and a seemingly
unstoppable corporate, as well as technical juggernaut.
The big question, of course, is whether the idealism that first fired up Page
and Brin can survive in a dirty corporate world where information is not just an
intellectual ideal, but also a legal and political hot potato involving profound
issues of privacy, intellectual property rights and freedom of speech. "You can
make money without doing evil," runs one of their most celebrated mantras. Does
that extend to signing a deal with China whereby its search functions will be
subject to state censorship? The furore over that particular decision, made at
the beginning of last year, still rages.
Google's activities thus touch on some of the key philosophical questions of our
digital age. Because of its power and prominence, it will also be the benchmark
by which we come to measure many of the answers.
Andrew Gumbel
Google is watching you,
I,
24.5.2007,
http://news.independent.co.uk/sci_tech/article2578479.ece
Like Yahoo, Google Adds
Customized Search Engine
October 24, 2006
The New York Times
By KATIE HAFNER
SAN FRANCISCO, Oct. 23 — Google introduced a tool Monday that
allows Web sites and blogs to offer visitors a customized version of its search
engine, narrowing down its vast index so the results are more relevant for
users.
Called the Google Custom Search Engine, the new product lets Web site owners
choose which pages they want to include in their index and rank the pages as
they like.
Yahoo has introduced a similar product, called Search Builder, but Google says
its service allows more customization.
“We have some features we feel are quite unique,” said Marissa Mayer, Google’s
vice president for search products and user experience. “We allow people to
restrict or prioritize search results based on the sites they’ve chosen.”
The new service is free. Web site publishers split the revenue from the text
advertisements that Google places on the search results through its AdSense
program. Nonprofit organizations, government agencies and educational
institutions are not required to include ads.
“The trouble with Google is you do get a lot of noise,” said Andrew Frank, a
research director in New York with Gartner, a market research firm. “Stuff gets
through that isn’t really relevant, either intentionally, or there are sometimes
ambiguities. This definitely helps improve the relevance and skip the noise.”
Mr. Frank said the new service had benefits for Google and its advertisers. “For
people in the AdSense network, it’s a way to increase inventory,” he said, “and
for Google it’s an extension of reach.”
Custom search engines are already up and running on a dozen or so sites.
Macworld.com has been using a preliminary version of the product for the last
month, customized to cover several Mac-oriented sites owned by Mac Publishing, a
unit of IDG.
Jason Snell, vice president and editorial director at Macworld, said his site
had been paying to use a search program by another company. But users had been
unhappy with the results, and “in the last month, we made the decision to drop
it like a rock,” Mr. Snell said. “We pulled it out and put Google in its place.
There’s no barrier to switching to Google because Google already knows about all
our pages.”
Mr. Snell said the customization tool was easy to configure. “I think you’ll see
a lot of people switch their search engine from whatever it might be to this,”
he said. “I think people have a comfort zone with Google searches.”
To build a customized index, users fill out a few Web-based forms, and are then
given the code for a search box that they can cut and paste into their own Web
pages.
“I think what’s going to drive usage is that it’s really easy for users to come
up with a search engine in a matter of minutes,” Ms. Mayer said.
Shares of Google hit a record intraday high of $484.64 on Monday, after a strong
earnings report last week. The stock closed at $480.71, up $21.11, or 4.6
percent.
Google said Thursday that its third-quarter profit nearly doubled from a year
earlier.
The growth came as Google’s largest rival, Yahoo, has suffered from weak sales
of search and display advertising. The profit report prompted several Wall
Street analysts to raise their ratings on Google stock.
Like Yahoo, Google Adds Customized Search Engine,
NYT,
25.10.2006,
https://www.nytimes.com/2006/10/24/
technology/24google.html
Related > Anglonautes >
Vocapedia
Google > Search engine >
Free speech, Censorship > China
technology
self-driving cars
economy
> jobs > robots
war >
weapons > robots
|